

Avant qu’un site puisse apparaître dans les SERP de Google (ou d’un autre moteur), le préalable est qu’il soit crawlé et indexé par les moteurs de recherche. Là, je ne vous apprends rien. Un petit rappel des fondamentaux de l’exploration et de l’indexation d’un site est toujours intéressant.
Un peu de théorie
Exploration
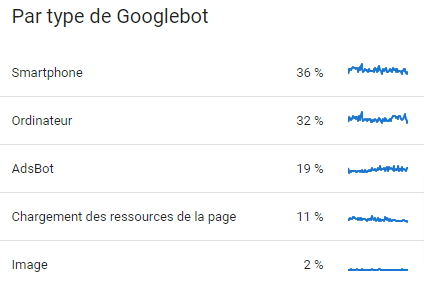
L’exploration correspond au passage de Googlebot sur votre site pour en extraire les éléments. Google utilise 5 types de bots différents pour explorer votre site.
Les classiques Googlebot Smartphone et Desktop et trois autres bots qui sont un peu moins connus : AdsBot pour tout ce qui concerne les Google Ads, Googlebot Image et un bot dont la tâche consiste à charger les ressources des pages de votre site.
L’objectif de ces robots est de parcourir les pages de votre site comme le ferait un utilisateur humain.
En explorant votre site Google à deux objectifs : découvrir de nouvelles pages ou actualiser les pages et ressources déjà connues.
Vous pouvez facilement connaître la répartition par objectifs dans la Google Search Console comme le montre l’illustration ci-dessous, dans Paramètres > Statistiques sur l’exploration.

Googlebot se base des algorithmes pour déterminer quelles pages vont être explorées et la fréquence d’exploration de votre site. Si vous souhaitez plus de précision sur le sujet, je vous conseille de lire ou de relire les articles suivants du blogarithme Népérien :
Google utilise un émulateur de Chrome pour explorer vos pages. Il n’est pas toujours à la même version que celle que vous pouvez utiliser pour naviguer sur le Web.
Comment sont déterminées les pages à ne pas explorer par Googlebot ?
En partant du principe qu’aucune gêne technique ne vient s’opposer à l’exploration des pages de votre site par Googlebot, voici trois cas qui empêchent tout crawl de vos pages :
Robots.txt
Google respecte scrupuleusement les directives disallow du fichier robots.txt à condition qu’elles aient une syntaxe parfaite (lisez notre article sur le standard robots.txt). Il y a un bémol de taille cependant : si une page est marquée comme disallow dans le robots.txt, elle n’est pas crawlée, mais elle pourra se retrouver indexée par Google si une autre page crawlable/indexable fait un lien vers cette page ! Il faut donc en tenir compte dans votre maillage.

Identification
Googlebot n’étant pas en mesure de simuler un identifiant de connexion valide (généralement un login associé à un mot de passe), toutes les pages nécessitant une identification préalable pour être consultées, ne sont naturellement pas accessibles aux moteurs de recherche.
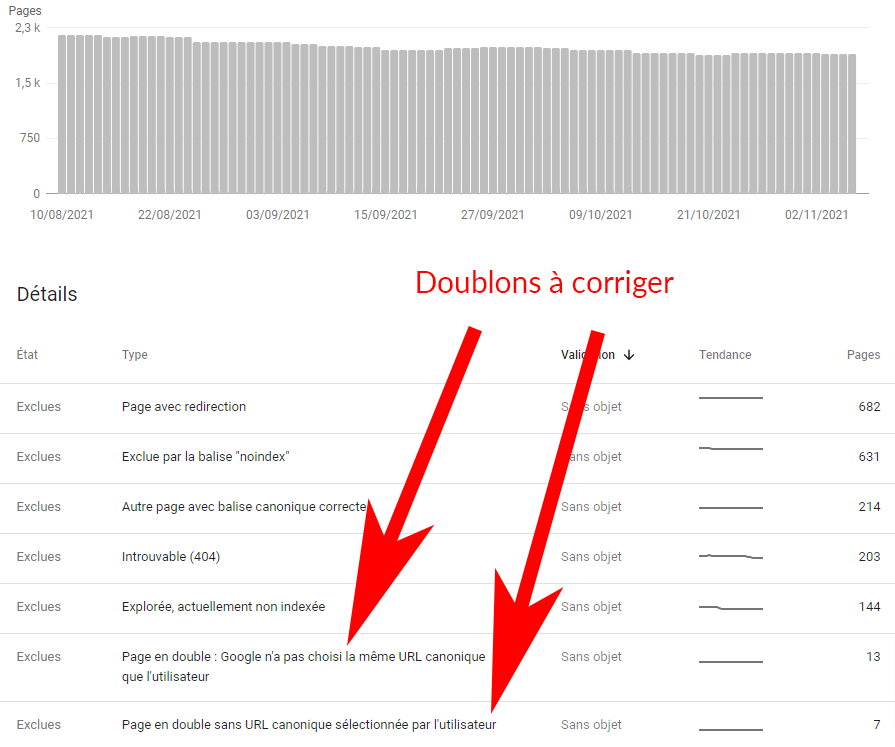
Page en doublon
Les pages considérées comme un doublon d’une autre page sont crawlées que très rarement (avec ou sans balise canonical, qui reste qu’une information donnée à Google – et en aucun cas une obligation – qu’il choisit ou non de respecter). L’outil d’inspection d’URL de la Search Console permet de rapidement savoir si Google a choisit la même page que vous comme page canonique.
Indexation
Une fois votre page explorée, Googlebot va la traiter pour en comprendre le contenu. Pour cela, il va analyser le code rendu, les balises et les attributs importants pour déterminer de quoi traite votre page, comme le texte, la balise title, les attributs alt, les médias (sauf rich media que Google ne sait pas actuellement analyser), Google sait presque tout analyser !
Google va ensuite déterminer si une page est un doublon d’une page déjà connue par lui, que cette page soit sur votre site ou de n’importe quel autre site connu de Google. S’il s’agit d’un doublon, il est fort probable que Google ne recrawle pas de si tôt la page concernée et qu’elle ne soit pas indexée. Google va regrouper la page qu’il considère la plus représentative (page canonique) et l’ensemble des doublons dans un même document. Pour Google, un document est une page Web seule ou un ensemble de pages constitué de la page canonique et de tous ces doublons.
Améliorer l’exploration et l’indexation de votre site
Améliorer l’exploration
Améliorer la crawlabilité d’une page n’est pas très compliqué. Il suffit de respecter scrupuleusement quelques règles :
- Supprimer tous les obstacles techniques à l’exploration ;
- Les URL à crawler doivent être dans un sitemap correct et déclaré à Google dans la Search Console ou dont le lien doit-être dans le fichier robots.txt dont Googlebot va systématiquement lire le contenu à chaque exploration de vos pages ;
- Vérifier que l’ensemble des ressources externes soient accessibles (images, CSS, scripts) ;
- Ne bloquez pas plus de pages que ce qui est strictement nécessaire dans le robots.txt ;
- Utilisez correctement les balises canonical, hreflang.
Si cela ne suffit pas :
- Demandez à Google de re-indexer une page en particulier en utilisant la fonction Demander une indexation de l’outil d’inspection d’URL de la Search Console (en savoir plus à ce sujet) ;
- Demandez à Google d’indexer un grand nombre de pages en lui envoyant un sitemaps et en “pingant” Google pour qu’il l’explore
http://www.google.com/ping?sitemap=URL/of/fileSi vraiment vous n’arrivez pas à faire indexer une page en particulier, vous pouvez la passer à l’outil d’inspection d’URL de la Search Console et Google devrait vous indiquer pourquoi il a choisi de ne pas l’indexer.

Améliorer l’indexation
Cela consiste à aider Google à comprendre le contenu de votre page. Pour cela, en plus du respect des consignes de Google aux Webmasters, de l’ensemble des techniques SEO connues et éprouvées, vous pouvez également utiliser la nouvelle version du guide des Quality Raters (ou evaluators) de Google que vous pouvez télécharger à partir de notre article qui lui est consacré.
Améliorer la visibilité de vos pages dans les SERP de Google
Nous n’allons pas passer en revue les critères communément admis comme influençant le positionnement de vos pages, ce n’est pas l’objectif de cet article. Par contre, en dehors de ces critères, il existe quelques règles de bon sens à respecter pour améliorer la diffusion de vos pages. Voici les principales :
- Si votre site est multilingue, vous devez utiliser des URL différentes pour chaque langue et parfaitement configurer la balise hreflang selon la norme ISO 639-1 pour la langue (paramètre obligatoire) et la norme ISO 3166-1 Alpha 2 pour la région (facultatif).
- Les Web Performance de vos pages doivent être au minimum au même niveau que celles des sites de vos principaux concurrents. Il faudra toujours un dernier et un premier en Web Perf, l’essentiel est d’être dans le peloton de tête. Tenter d’aller au-delà sera très chronophage pour un ROI vraisemblablement négatif. La consigne : ne vous laissez pas distancer sur ces KPI, pas plus !
- Vos pages doivent être parfaitement adaptées aux mobiles. Vous pouvez facilement le vérifier avec l’outil consacré au test d’optimisation mobile de Google.
- Les données structurées qui sont trop souvent mises de côté, alors qu’il s’agit d’un formidable moyen d’améliorer la visibilité de vos pages dans les SERP en permettant à Google de mieux en connaître et comprendre le contenu.
Vous connaissez maintenant les principes d’exploration et d’indexation de Google. À vous de jouer !
Ce contenu vous a plu ?
Inscrivez-vous gratuitement à notre newsletter et recevez chaque semaine l’actualité du SEO directement dans votre boîte email. Vous pouvez vous désabonner à tout moment !