

La plupart d’entre vous connaissent la balise meta robots, qui permet de contrôler dans le header d’une page HTML le comportement des bots de moteurs de recherche.
Voila par exemple une syntaxe basique pour ajouter une instruction noindex :

Oui mais cela ne fonctionne que s’il s’agit de pages HTML. Or il peut arriver que l’on souhaite contrôler aussi l’indexation et le comportement des robots pour d’autres types de fichiers, comme des images ou des pdfs.
Or ces fichiers ne peuvent pas contenir du code HTML.
Les moteurs de recherche ont donc décidé d’instaurer un système alternatif qui permet d’ajouter ce genre d’instructions dans l’en-tête http renvoyée par le serveur web. La syntaxe est proche et les valeurs d’attribut possibles sont similaires.
Cela donne ceci :
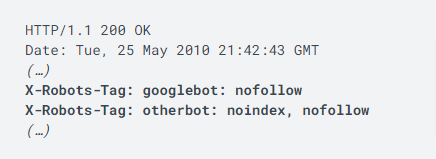
Mais en pratique, il est donc possible pour un fichier HTML de placer ces instructions :
- soit dans l’en-tête Http:
- soit dans le header du code HTML
- et bien sûr, on peut faire les deux à la fois.
Mais est-ce que les deux systèmes sont interchangeables ? Et que se passe-t’il quand les deux types d’ instructions se contredisent ?
Le X-Robots-Tag est lu en premier lors du crawl
Compte tenu des différences techniques entre les deux implémentations, Googlebot lira toujours le X-Robots-Tag avant de lire la meta robots qu’il devra parser d’abord pour le prendre en compte.
En pratique, cela n’aura aucune incidence, in fine Google lira les deux types de directives avant de décider quoi faire. Les deux solutions sont équivalentes et presque interchangeables.
Donc vous pouvez utiliser l’une ou l’autre des solutions pour les pages HTML, à votre convenance.
Techniquement, le X-Robots-Tag est parfois la seule solution, ou la plus facile à implémenter. Dans d’autres cas, c’est la meta robots qui sera plus simple à mettre à place. Vous pouvez choisir la solution qui vous arrange.
Notez quand même qu’il facile d’oublier ce qui apparait dans un X-robots-Tag, c’est donc une bonne idée de se servir d’une extension de navigateur pour identifier les pages bloquées par une directive, et qui vous donne facilement l’origine du blocage.
Je vous conseille par exemple cette extension très pratique :
https://www.samgipson.com/robots-exclusion-checker-chrome-extension/
Et que se passe-t’il en cas de conflit entre les différents types d’instruction ?
Si vous indiquez noindex d’un côté et index de l’autre, vous demandez à Google de respecter des injonctions contradictoires.
En principe, Google va respecter la directive la plus restrictive pour lui.
Donc si vous avez mis un « index » dans le X-robots-Tag, et un « noindex » dans la meta robots, c’est la noindex qui sera respectée.
Mais cela ne marche pas avec certitude, donc il faut absolument éviter de créer des instructions contradictoires.
Vous êtes prévenus !
Pour en savoir plus :
https://developers.google.com/search/docs/crawling-indexing/robots-meta-tag?hl=fr
Ce contenu vous a plu ?
Inscrivez-vous gratuitement à notre newsletter et recevez chaque semaine l’actualité du SEO directement dans votre boîte email. Vous pouvez vous désabonner à tout moment !
« La directive la plus restrictive est prise en compte ».
Merci pour cette info.