

Les outils à base d’IA suscitent pas mal de fantasmes, mais ils ont aussi clairement des failles qui peuvent être exploitées à des fins malveillantes.
Google a décidé d’utiliser en 2022 des « red teams » pour renforcer sa sécurité. Les « équipes rouges » sont des hackers internes ou externes employés pour une entreprise pour réaliser des attaques malveillantes contre son site ou ses logiciels, afin de tester si les mesures de sécurité prises sont suffisantes.
Pour en savoir plus sur cette stratégie, voici un article qui décrit le Red Teaming version Google dans sa version de départ :
https://blog.google/technology/safety-security/meet-the-team-responsible-for-hacking-google/
La firme de Mountain View a décidé il y’a quelques semaines (en juillet 2023) de monter une Red Team pour tester la sécurité et la résilience de ses outils d’IA.
En effet, les algorithmes d’intelligence artificielle peuvent être « attaqués » comme n’importe quel outil digital. Mais leur particularité c’est que leur caractère récent n’a pas forcément permis d’explorer et d’identifier tous les types d’attaque. Et que certains « hacks » déjà identifiés sont spécifiques.
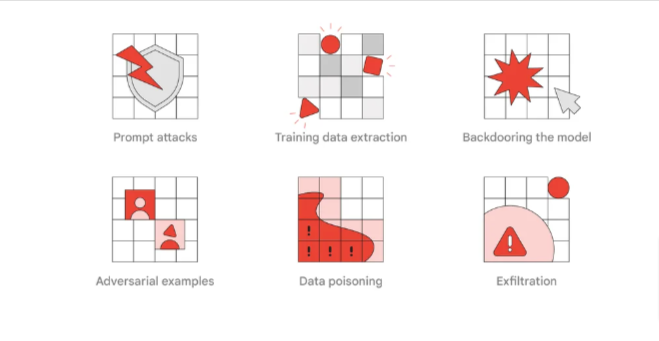
Parmi les attaques les plus connues, on peut citer :
- les « prompt injections » ou « prompt attacks« , c’est à dire l’emploi d’instructions qui vont tromper les procédures de sécurité des outils d’IA
- le « data poisoning », qui consiste à laisser une IA en phase d’apprentissage « avaler » des données conçues pour produire un résultat malveillant, ou l’empêcher de fonctionner normalement
- l’extraction de données d’entrainement a pour objectif de récupérer les données brutes qui ont servi à l’entrainement. C’est potentiellement dangereux car ces données brutes peuvent contenir des données personnelles ou confidentielles
- le « backdooring du model » consiste à utiliser une instruction qui permet d’avoir un accès avec de large droits sur le modèle, ce qui permet aux hackers de modifier les caractéristiques du modèle, d’injecter du code malicieux ou d’en contrôler les résultats en sortie
- les attaques par « exemples contradictoires » (adversarial examples) sont beaucoup plus subtiles. Elles consistent à ajouter des données invisibles (cachées dans le « bruit » d’une image ou d’un fichier son ou video, ou tout autre fichier numérique) qui une fois analysée par l’IA, vont produire un résultat inattendu.
Un exemple d’attaque par adversarial examples :
Etonnant non ? Il suffit d’ajouter un sticker sur la table pour que la banane ne soit plus reconnue.
Est-ce que cela change quelque chose sur Bard, ou la SGE?
Pour l’instant non, mais cela explique pourquoi des sociétés comme Google ou Microsoft sont prudentes avant de lancer leurs outils à base d’IA. La vulnérabilité de ces outils à des attaques classiques ou nouvelles est encore très grande à ce stade. Il faut le garder en tête avant de confier ses données, sa sécurité et ses processus décisionnels à des outils qui peuvent être manipulés par des personnes malveillantes.
Pour en savoir plus :
Une video sur l’activité de la Red Team
Et un rapport en pdf qui vous en dit plus sur les typologies d’attaque sur lesquelles la Red Team travaille.
https://services.google.com/fh/files/blogs/google_ai_red_team_digital_final.pdf
Ce contenu vous a plu ?
Inscrivez-vous gratuitement à notre newsletter et recevez chaque semaine l’actualité du SEO directement dans votre boîte email. Vous pouvez vous désabonner à tout moment !