
Il est assez facile de déterminer si un site web a été élaboré à partir d’un framework JavaScript. En revanche, repérer les pages, les sections ou les entités et balises HTML qui sont modifiées dynamiquement via JavaScript s’avère plus complexe. Pour cela, un crawl spécifique est nécessaire. Dans la continuité de notre article sur le JavaScript et SEO, je vous propose de voir comment un crawl avec rendu du JavaScript peut être fait à l’aide de Screaming Frog.
Crawler un site JavaScript avec Screaming Frog
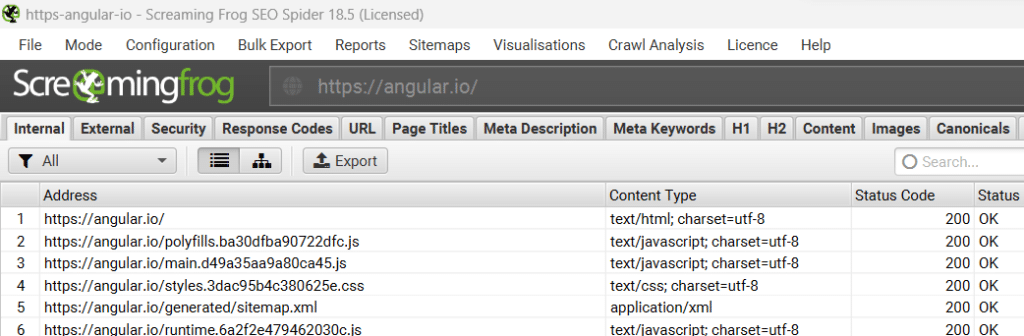
Le mode de rendu d’un crawl par défaut de Screaming Frog est « Text only » (texte uniquement). Dans ce mode, le crawl d’un site CSR (voir notre article), donne des résultats très limités.
Dans l’illustration ci-dessous, on remarque très vite que suite au crawl de la page d’accueil, nous n’avons pas d’autres pages HTML, mais directement des ressources CSS et JS et le sitemap.
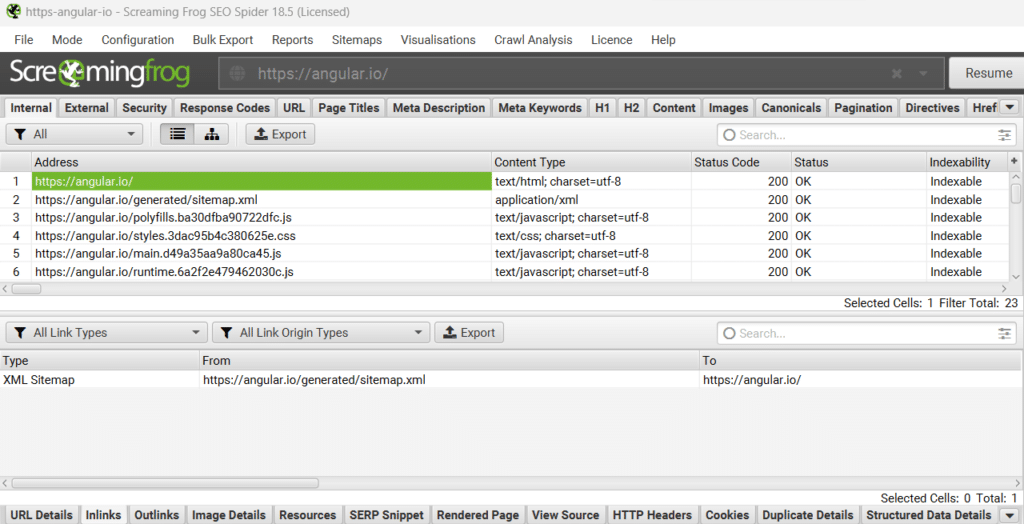
Nous savons tous que les liens internes et les liens de navigations sont essentiels pour que les moteurs de recherche puissent découvrir les différentes pages qui composent un site Web. Mais aussi pour avoir un bon aperçu de la structure du site entre autres.
En examinant les liens internes entrants (inlinks) de la page d’accueil de notre site exemple : angular.io, on remarque que celle-ci ne reçoit qu’un seul lien entrant : en provenance du sitemap. Est-ce que cela signifie que les différentes pages du site ne font pas de lien remontant vers la page d’accueil ? Nous y répondrons un peu plus loin dans notre article.
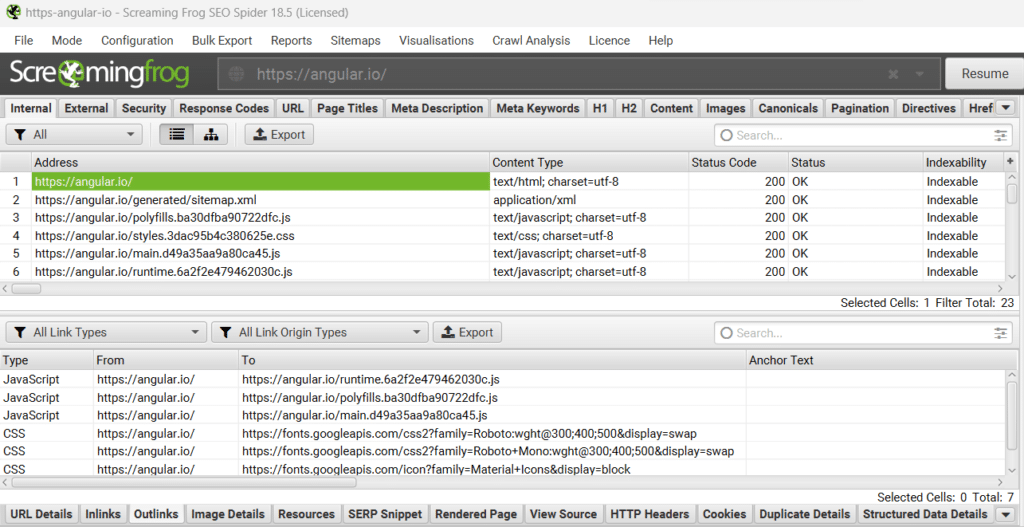
De la même manière, on remarque que la page d’accueil fait des liens internes sortants (outlinks) que vers des ressources JS et CSS, aucun lien HTML avec une ancre cliquable !
Analyser un site JavaScript avec Screaming Frog
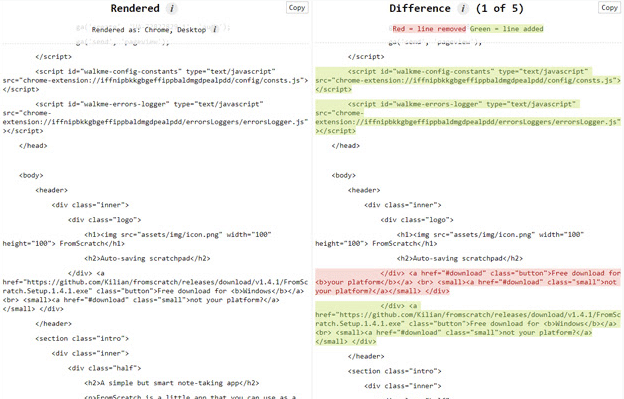
Screaming Frog permet de facilement identifier le contenu rendu en JavaScript et de faire une comparaison avec le rendu HTML.
J’en profite pour vous parler d’un add-on Chrome qui permet aussi de le faire en affichant le code source généré et le code source rendu d’une page Web. Il s’agit de l’extension View Rendered Source, que je vous conseille également d’installer, car très pratique.
« View Rendered Source » a pour objectif principal de décrypter comment le navigateur assemble et affiche le code HTML initial d’une page dans le DOM, y compris les transformations réalisées par JavaScript.
Revenons à Screaming Frog.
Pour identifier l’impact du JavaScript du site à analyser, vous devez configurer le rendu sur JavaScript dans le menu Configuration > Spider > Rendering de Screaming Frog.
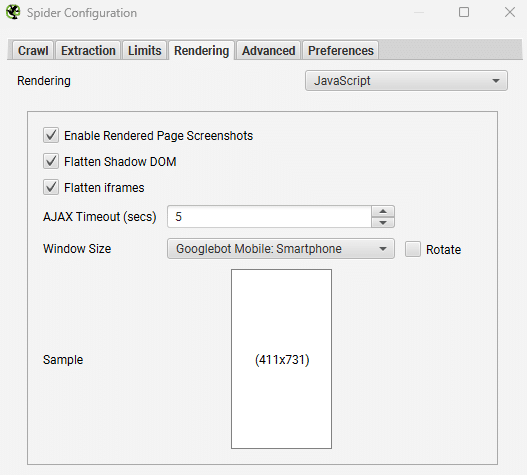
Ensuite, lancez le crawl comme habituellement. Cela va permettre au spider d’explorer le contenu HTML original et le contenu rendu. Cela vous permettra de savoir facilement si du contenu ou des liens ne sont disponibles que côté client (CSR) et par ailleurs de vous lister les ressources dépendantes.
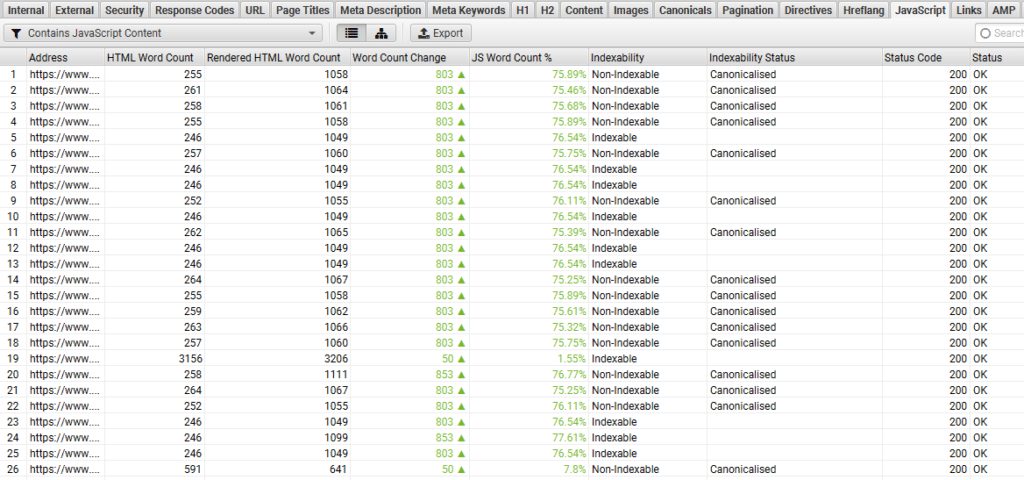
Dans l’onglet JavaScript de Screaming Frog, on peut très facilement isoler le contenu :
- Avec des liens JavaScript
- Avec du contenu JavaScript
- Avec des balises canonicals ou des attributs noindex, nofollow modifiés ou différents entre la version HTML et la version rendue
- Même chose pour les balises essentielles pour le SEO ou la SERP : title, h1 et méta description
- Sans oublier les ressources qui sont inaccessibles (bloquées par le robots.txt par exemple)
Quand est-il recommandé de faire un crawl avec rendu JavaScript ?
Vous avez remarqué, que lancer un crawl avec rendu JavaScript demande beaucoup plus de temps d’un crawl en mode texte.
En effet, le crawler doit faire a minima deux passages sur chaque page au lieu d’un et demander à Chromium d’en faire le rendu avant de comparer les deux versions. Cela demande beaucoup plus de ressources et de temps. Le rendu se fait à l’aide d’un headless browser en arrière-plan afin de générer le DOM.
Un crawl JavaScript est recommandé si le site à auditer comporte des données manipulées dynamiquement par JavaScript. Vous pouvez déjà avoir une idée de ce point en examinant les technologies utilisées par le site, à l’aide de l’extension Chrome Wappalyzer par exemple. Cette extension vous permettra de savoir si le site utilise des technologies JavaScript comme React ou Angular, Vue, etc.
Comment configurer Screaming Frog pour un crawl avec rendu JavaScript ?
Vous trouverez ci-dessous la configuration nécessaire pour faire un crawl avec rendu JavaScript à partir de Screaming Frog.
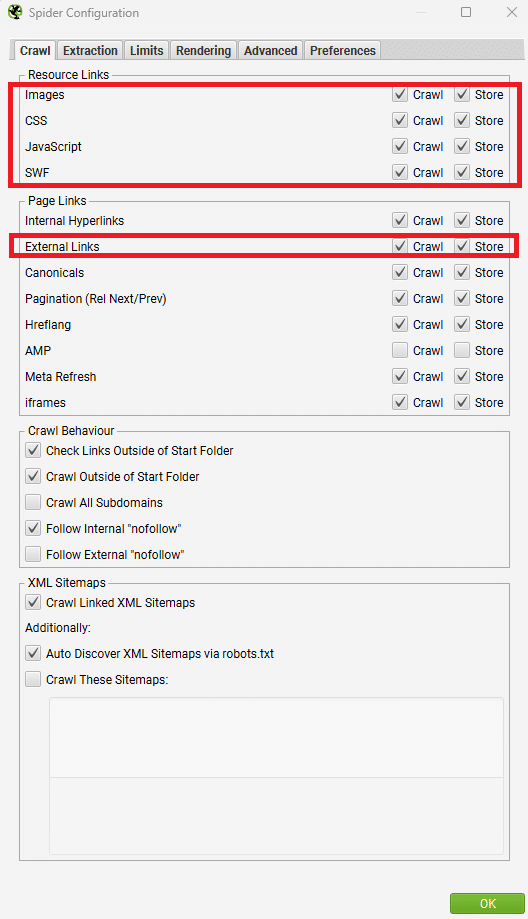
- Menu > Configuration > Spider > Rendering : mettre le rendering sur JavaScript
- Menu > Configuration > Spide > Rendering : mettre Window Size sur Googlebot Mobile Smartphone
- Menu > Configuration > Spider > Crawl, l’ensemble des « Ressource Links » + « External links » doivent avoir Crawl et Store de cochés
Comment optimiser les éléments rendus en JS ?
Votre crawl avec rendu JavaScript est terminé et l’analyse effectuée. Rendez-vous dans l’onglet JavaScript de Screaming Frog.
Comme mentionné plus haut, vous pouvez filtrer les éléments suivants :
Pages dont les ressources sont bloquées : Pages dont les ressources (telles que les images, JavaScript et CSS) sont bloquées par le fichier robots.txt. Cela peut poser un problème, car les moteurs de recherche peuvent ne pas être en mesure d’accéder à des ressources essentielles pour rendre les pages avec précision. Mettez à jour le fichier robots.txt pour permettre à toutes les ressources critiques d’être explorées et utilisées pour le rendu du contenu du site web. Les ressources qui ne sont pas essentielles (par exemple, l’intégration de Google Maps) peuvent être ignorées.
Contient des liens JavaScript : Pages contenant des hyperliens qui ne sont découverts dans le rendu HTML qu’après l’exécution de JavaScript. Ces hyperliens ne figurent pas dans le code HTML brut. Bien que Google soit capable de rendre les pages et de voir les liens côté client uniquement, pensez à inclure les liens importants côté serveur dans le HTML brut.
Contient du contenu JavaScript : Pages contenant un corps de texte qui n’est découvert dans le rendu HTML qu’après l’exécution du JavaScript. Bien que Google soit en mesure de rendre les pages et de voir le contenu côté client uniquement, pensez à inclure le contenu important côté serveur dans le code HTML brut.
Noindex dans le HTML original : Pages qui contiennent une balise noindex dans le code HTML brut, et non dans le code HTML rendu. Lorsque Googlebot rencontre une balise noindex, il ignore le rendu et l’exécution de JavaScript. Étant donné que Googlebot ignore l’exécution de JavaScript, l’utilisation de JavaScript pour supprimer le « noindex » dans le code HTML rendu ne fonctionnera pas.
Examinez attentivement les pages contenant la balise « noindex » dans le code HTML brut, qui sont censées ne pas être indexées. Supprimez le « noindex » si les pages doivent être indexées.
Nofollow dans le HTML original : Pages qui contiennent un nofollow dans le HTML brut, et non dans le HTML rendu. Cela signifie que tout hyperlien dans le HTML brut avant l’exécution de JavaScript ne sera pas suivi. Les pages contenant un nofollow dans le HTML brut sont censées ne pas être suivies. Supprimez le « nofollow » si les liens doivent être suivis, explorés et indexés.
Canonique uniquement dans le HTML rendu : Pages qui contiennent une canonical uniquement dans le HTML rendu après l’exécution de JavaScript. Google peut traiter les balises canoniques dans le code HTML rendu, mais il ne recommande pas de s’appuyer sur JavaScript et préfère qu’elles soient placées plus tôt dans le code HTML brut. Des problèmes de rendu, des conflits ou des balises rel= »canonical » multiples peuvent conduire à des résultats inattendus. Incluez un lien canonique dans le code HTML brut (ou dans l’en-tête HTTP) pour que Google puisse le voir et évitez de vous fier exclusivement au lien canonique dans le code HTML rendu.
Non correspondance canonique : Pages contenant un lien canonique différent dans le code HTML brut et dans le code HTML rendu après l’exécution de JavaScript. Google peut traiter les liens canoniques dans le code HTML rendu après que JavaScript a été traité, mais des balises de lien rel= »canonical » conflictuelles peuvent conduire à des résultats inattendus. Veillez à ce que le lien canonique correct soit présent dans le HTML brut et dans le HTML rendu afin d’éviter des signaux contradictoires aux moteurs de recherche.
Titre de la page uniquement dans le code HTML rendu : Pages qui contiennent un titre de page uniquement dans le code HTML rendu après l’exécution de JavaScript. Cela signifie qu’un moteur de recherche doit rendre la page pour la voir. Bien que Google soit en mesure de rendre les pages et de voir le contenu côté client seulement, pensez à inclure le contenu important côté serveur dans le code HTML brut.
Titre de page mis à jour par JavaScript : Pages dont le titre est modifié par JavaScript. Cela signifie que le titre de la page dans le code HTML brut est différent du titre de la page dans le code HTML rendu. Bien que Google soit en mesure de rendre les pages et de voir le contenu côté client uniquement, pensez à inclure le contenu important côté serveur dans le HTML brut.
Méta description uniquement dans le HTML rendu : Pages qui contiennent une méta description uniquement dans le HTML rendu après l’exécution du JavaScript. Cela signifie qu’un moteur de recherche doit rendre la page pour la voir. Bien que Google soit en mesure de rendre les pages et de voir le contenu côté client seulement, il convient d’envisager d’inclure le contenu important côté serveur dans le code HTML brut.
Méta description mise à jour par JavaScript : Pages dont les méta descriptions sont modifiées par JavaScript. Cela signifie que la méta description dans le HTML brut est différente de la méta description dans le HTML rendu. Bien que Google soit en mesure de rendre les pages et de voir le contenu côté client uniquement, pensez à inclure le contenu important côté serveur dans le HTML brut.
H1 uniquement dans le HTML rendu : Pages qui contiennent un h1 uniquement dans le HTML rendu après l’exécution de JavaScript. Cela signifie qu’un moteur de recherche doit rendre la page pour la voir. Bien que Google soit capable de rendre les pages et de voir le contenu côté client exclusivement, pensez à inclure le contenu important côté serveur dans le HTML brut.
H1 mis à jour par JavaScript : Pages dont les h1 sont modifiés par JavaScript. Cela signifie que le h1 dans le HTML brut est différent du h1 dans le HTML rendu. Bien que Google soit en mesure de rendre les pages et de voir le contenu côté client uniquement, pensez à inclure le contenu important côté serveur dans le HTML brut.
Utilise les anciennes URL AJAX Crawling Scheme : URL qui utilisent encore l’ancienne AJAX Crawling Scheme (une URL contenant un fragment de hachage # !) qui a été officiellement dépréciée en octobre 2015. Mettez à jour les URL pour suivre les meilleures pratiques JavaScript sur le web aujourd’hui. Envisagez le rendu côté serveur ou-le pré-rendu lorsque c’est possible, et-le rendu dynamique comme solution de contournement.
Utilise l’ancien schéma de crawling AJAX Meta Fragment Tag : Les URL incluent un meta fragment tag qui indique que la page utilise toujours l’ancien schéma de crawling AJAX qui a été officiellement déprécié depuis octobre 2015. Mettez à jour les URL pour suivre les meilleures pratiques JavaScript sur le web aujourd’hui. Envisagez le rendu côté serveur ou le pré-rendu lorsque c’est possible, et le rendu dynamique comme solution de contournement. Si le site comporte encore l’ancienne balise méta fragment par erreur, celle-ci doit être supprimée.
Nous reviendrons, dans un prochain article, plus en détail sur l’analyse du code original vs le code rendu et des optimisations possibles qu’il est possible de faire assez simplement.