

Le WRS, c’est le « Web Rendering Service », le service de rendition qui permet à Googlebot de voir votre page web exactement comme elle apparait dans votre navigateur.
Le WRS est exécuté après un crawl du code HTML et des ressources téléchargeables de votre page web. Et il est chargé d’interpréter et d’exécuter le code Javascript et les CSS présents sur la page.
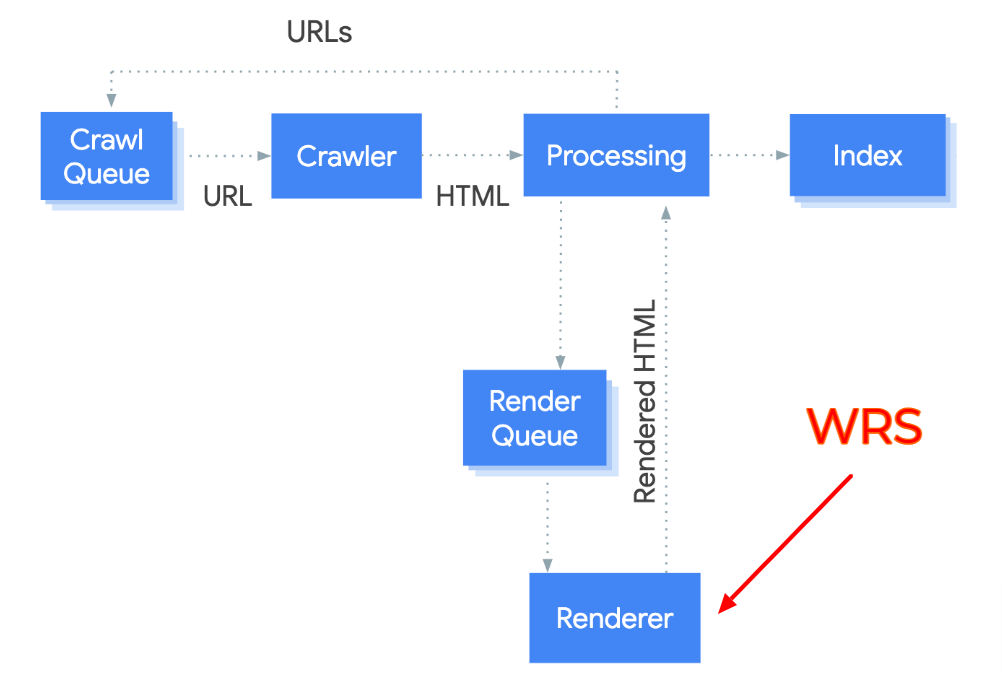
On sait que le WRS fonctionne à partir d’un navigateur « headless » qui est, en l’occurrence, la dernière version stable de Chromium.
Chromium, c’est la version open source de Chrome, qui est également utilisée par Bingbot pour les mêmes tâches.
Mais pour des raisons pratiques, Googlebot n’utilise pas Chromium EXACTEMENT comme votre navigateur web, et cela peut avoir des conséquences qu’il est utile de connaître…
Google gère son propre cache pour les ressources
Google a décidé de publier plusieurs posts en Décembre sur les problématiques de cache. Dans son post du 3 décembre 2024, que vous trouverez ici :
https://developers.google.com/search/blog/2024/12/crawling-december-resources?hl=en
Martin Splitt et Gary Illyes ont apporté quelques précisions complémentaires sur la façon dont le WRS fonctionne.
Lors de la renditon de la page, les scripts peuvent appeler d’autres scripts et fichiers dynamiquement pour effectuer une rendition complète de la page.
Pour économiser du budget de crawl, les ressources de ce type ne sont pas appelées à chaque appel du WRS : elles sont mises en cache par Google, et ce pour une durée qui peut aller jusqu’à 30 jours.
Précision importante : Google ne tient aucun compte de vos instructions de mise en cache.
Les recommandations de Google
Google donne trois recommandations pour éviter de consommer trop de crawl budget ou éviter de provoquer des blocages empêchant une rendition normale :
- Utilisez le moins de ressources possible pour offrir aux utilisateurs une expérience agréable ; moins le rendu d’une page nécessite de ressources, moins la rendition consomme de budget de crawl
- Utilisez la méthode de « cache busting » à base de paramètres ou en changeant le nom de fichier avec prudence: si les URL des ressources changent, Google peut avoir besoin d’explorer à nouveau les ressources, même si leur contenu n’a pas changé. Cette opération consomme évidemment du budget de crawl.
- Hébergez les ressources sur un nom d’hôte différent de celui du site principal, par exemple en utilisant un CDN ou en hébergeant simplement les ressources sur un sous-domaine différent. Cela permet de déplacer la charge relative au budget d’exploration vers l’hôte qui sert les ressources.
Sur le point 3, Google a rectifié le tir le 6 décembre en précisant que c’était rentable pour les ressources de type images ou videos, mais pas pour les javascripts, les CSS, les Json et les xml car cela dégradait les performances.
Martin Splitt a également précisé dans les commentaires sur cette publication que bloquer des ressources à l’aide d’une directive dans le robots.txt n’était pas une bonne idée, surtout si ces fichiers sont utiles pour que la rendition soit correcte.
Pourquoi c’est important ?
Si le contenu de vos pages web est généré partiellement ou complètement dans le navigateur de l’internaute, et non côté serveur (donc en CSR et non en SSR pour employer le jargon approprié), c’est une bonne idée de simplifier la vie de Googlebot et du WRS.
Contrairement au discours que les porte parole de Google ont tenu depuis son apparition, le WRS a ses limites, et il est assez facile de « buter » contre ces limites et d’avoir des problèmes d’indexation. Donc appliquer ces recommandations est une bonne idée.
Par ailleurs, connaître ce comportement peut vous aider à comprendre pourquoi certaines modifications ne sont pas prises en compte rapidement par Google. Pensez dans ce cas à changer le nom de votre ressource pour forcer sa mise à jour.
Ce contenu vous a plu ?
Inscrivez-vous gratuitement à notre newsletter et recevez chaque semaine l’actualité du SEO directement dans votre boîte email. Vous pouvez vous désabonner à tout moment !