

Il y’a quelques mois le petit monde du SEO s’était enflammé suite aux Google Leaks. Si vous avez raté / oublié cet évènement, voici le lien vers l’article que nous avions fait à l’époque sur le Blogarithme Népérien :
Mais avec un peu de recul, les informations que l’on a pu tirer de ces documents manquent de contexte, ce qui rend leur exploitation pour des tactiques SEO impossibles. Cela permet tout juste de comprendre un mieux le fonctionnement particulier de Google Search.
Même sur ce dernier point, les principales conclusions que Rand Fishkin et Michael King sont parvenus à en tirer dans leurs articles dévoilant les Leaks s’appuient sur des informations qui ne figurent absolument pas dans les Leaks. En réalité, quand ils parlent de Navboost, Glue ou Tangram, ils reprennent des informations divulguées fin 2023, lors du témoignage de Pandu Nayak (à l’époque VP Search de Google) devant la justice américaine.
Quand Google se voit forcer de communiquer des informations internes, à son corps défendant
Ces temps-ci, la principale source d’informations cachées sur le fonctionnement de Google Search, ce sont les pièces que la Justice Américaine a imposé à Google de divulguer. La procédure accusatoire aux Etats Unis permet aux parties adverses de forcer l’autre partie à produire des documents ou des éléments de preuve, pourvu que cette demande soit acceptée par le Juge.
C’est ainsi que, lors de différentes procédures, Google a dû communiquer à la justice (et aux plaignants) des documents et des informations internes : chiffres, emails, rapports, deck powerpoints etc…
Les tribunaux US ont l’habitude de rendre l’accès public à certains de ces documents possibles. Seules les informations dont la divulgation ne serait pas dommageable pour la partie qui les a produites sont publiées dans ce cadre. Et il est d’usage de « censurer », parfois abondamment, les passages des documents qui contiennnent des informations qui pourraient être utilisées contre l’une des parties, par des concurrents par exemple/
Par ailleurs, la procédure accusatoire donne lieu également à des séances où des témoins clés sont passés sur le grill par les avocats de la partie adverse, et sont forcés de répondre à des questions souvent embarassantes, car la sanction en cas de parjure est dissuasive.
C’est dans ce cadre que le VP Search de Google a du lâcher des informations clés sur l’algorithme. Informations qui ont été publiées dans les transcriptions des interrogatoires qui ont été rendus publics, contrairement aux documents qui ont servi à sélectionner les questions à M. Nayak.
Ce que l’on apprend dans la décision du juge Mehta
Le 5 août dernier, la décision finale dans le procès DOJ vs Google a été publiée. A cette occasion, un document de 285 pages à été fourni pour présenter l’argumentation qui a abouti à cette décision du Juge Mehta. Et encore une fois, ce document contient quelques informations qui sont à elles seules des pépites intéressantes à signaler.
Si vous souhaitez consulter ce document, voici le lien pour le télécharger
Et voici un florilège des informations qui sont restituées dans ce document. Elles résument des éléments figurant dans des documents non communiqués au public, ou les contextualisent. Mes commentaires sont en italiques.
L’algorithme de classement fait un usage intensif des données utilisateurs
Cette procédure contre Google a permis de révéler le niveau d’utilisation des données utilisateurs dans son algorithme de classement.
Pourquoi ? Parce que le DOJ a utilisé comme argument pour prouver la violation des lois antitrust et antimonopole américaines, l’avantage concurrentiel énorme apporté par la possibilité que Google a d’exploiter un volume de données utilisateurs incomparable par rapport à ses concurrents. Et donc une bonne partie des investigations a porté sur ce que Google faisait des données utilisateurs, et à quel point cela leur donnait un avantage.
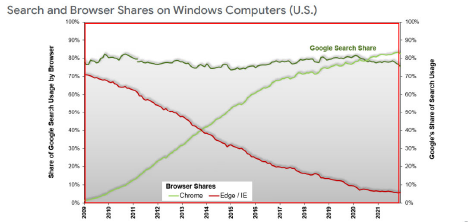
Google dispose de deux sources clé de données utilisateurs : le tracking sur son moteur de recherche (80 % de part de voix aux USA, et Chrome, qui est devenu le navigateur utilisé par 85% des américains ! (source : Google Search Engine Monopoly Ruling)
Les données utilisateurs déterminent les priorités de crawl et de recrawl
(Point 91 de la décision) : les données utilisateurs aident les moteurs de recherche à identifier les sites et les pages à crawler en priorité, ou à recrawler. (source : un document de John Giannandrea)
Jusqu’ici, cette approche n’avait pas été évoquée par Google. C’était plutôt le pagerank qui était présenté comme le principal critère. C’est peut-être toujours le cas. On sait juste maintenant que les données de clics provenant de Google ou de Chrome sont exploitées dans les scores utilisées par l’ordonnanceur de Googlebot pour définir les priorités de crawl et recrawl.
Les données de sessions de recherche sont utilisées lors de l’indexation
(point 92) : si les données générales sur le trafic du site sont peu utilisées dans la phase de création de l’index du moteur, les données de session de recherche sont, elles, beaucoup plus utilisées.
Les données de sessions de recherches comprennent : les requêtes effectuées par les internautes, puis les clics et toutes les actions que Google peut tracker sur la page de résultats au cours de la même session de recherche.
Cela permet au moteur de recherche d’identifier les requêtes qui méritent de figurer dans l’index. On apprend aussi que les index chez Google sont découpés en plusieurs niveaux.
Les plus anciens se souviennent des deux index (primaire et secondaire) dans les premières versions de Google. Un brevet avait laissé penser que Google avait basculé sur un système d’index multiples à plusieurs niveaux plus sophistiqué : https://patents.google.com/patent/US20150186453A1/en . Gary Illyes l’avait confirmé en 2021. C’est donc juste une nouvelle confirmation de cette particularité.
QBST : Query Salient Based Terms
(point 95) : Les Query Salient Based Terms (Les termes saillants basés sur les requêtes), ou QBST, sont un signal de Google qui aide à répondre aux requêtes en identifiant les mots et les paires de mots qui « devraient apparaître en bonne place sur les pages web » en identifiant les mots et les paires de mots qui « devraient figurer en bonne place sur les pages web qui sont pertinentes pour cette requête ».
Cet algorithme est entrainé sur 13 mois de données utilisateurs.
On soupçonnait Google d’utiliser cette approche, en raison de la publication d’un brevet sur cette fonctionnalité, et parce que beaucoup de papiers scientifiques montraient que les QBST faisaient partie de l’état de l’art dans les moteurs de recherche grand public :
https://patents.google.com/patent/US9251473B2/en
Navboost : un signal très important
Navboost est un autre signal qui associe les requêtes et les documents en mémorisant les données de clics de l’utilisateur.
Les données relatives aux clics de l’utilisateur permettent à Google de se souvenir des documents sur lesquels les utilisateurs ont cliqué après avoir saisi une requête et d’identifier lorsqu’un seul document est cliqué en réponse à plusieurs requêtes.
NavBoost « était considéré comme très important ».
Avant 2017, Google a entraîné Navboost sur la base de 18 mois de données d’utilisateurs. Depuis lors, elle a entraîné Navboost sur 13 mois de données d’utilisateurs.
Treize mois de données utilisateur acquises par Google équivalent à plus de 17 ans de données sur Bing.
Les évolutions récentes utilisent un volume de données utilisateur moins important
Les signaux de classement plus récents développés par Google reposent moins sur les données des utilisateurs. Il s’agit notamment de RankBrain, DeepRank, RankEmbed, RankBERT et MUM.
Connus sous le nom de systèmes de « généralisation », ces signaux « ne sont peut-être pas très bons pour mémoriser des faits, mais ils sont vraiment bons pour comprendre le langage ».
Ces systèmes sont « conçus pour combler les lacunes dans les données [de clics] » ; ils permettent à Google de généraliser à partir de situations pour lesquelles il dispose de données vers des situations pour lesquelles il n’en dispose pas.
Bien que ces systèmes plus récents soient moins dépendants des données des utilisateurs, ils ont été conçus à partir de ces données et continuent d’être formés à partir de celles-ci, bien qu’en utilisant un volume moins important. […] (les signaux plus anciens utilisent jusqu’à 1 trillion d’exemples, alors que les algorithmes plus récents n’en nécessitent qu’un milliard) ; […] (« L’apprentissage à partir de ce retour d’information de l’utilisateur est peut-être la principale façon dont le classement des sites Web s’est amélioré depuis 15 ans »).
Ces nouveaux systèmes n’ont pas remplacé QBST et Navboost
Les signaux LLM plus récents n’ont pas remplacé Navboost et QBST dans l’algorithme de classement. (« Navboost reste l’un des composants de classement les plus puissants historiquement[.] »). Ils n’ont pas non plus rendu les systèmes de généralisation obsolètes.
Les LLM sont utilisés comme des « signaux supplémentaires qui sont mis en balance les uns avec les autres ainsi qu’avec d’autres signaux
Les systèmes traditionnels comme Navboost peuvent également battre les LLM (et même les systèmes de généralisation) dans certains aspects de la production de SERP, comme la fraîcheur
Attention à ne pas se tromper de conclusions sur l’utilisation des données utilisateurs
Dans le document on trouve plein de références à des documents produits dans la procédure, dont certains sont publics. En lisant ces documents de référence, on s’aperçoit que si des morceaux de l’algorithme utilisent des données utilisateurs de manière intensive, c’est toujours :
- soit pour entrainer des algorithmes afin de pouvoir les utiliser au sein de l’algorithme de classement
- soit pour améliorer les algorithmes de classement en identifiant les cas où la réponse n’est pas pertinente
- Soit en sélectionnant des jeux de données issus de l’index pour déterminer les réponses candidates pour figurer dans les premières pages de résultat (Navboost)
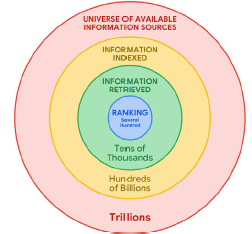
Le processus de selection (culling) des résultats remontés par une recherche dans Google : sur les centaines de milliards de pages indexées, QBST et l’indexation par niveaux permet de sélectionner quelques dizaines de millers de pages indexées éligibles pour figurer en tête des résultats. Et Navboost permet de sélectionner parmi les résultats du cercle vert, quelques centaines de pages indexées pour aboutir aux rond bleu. Figure apparaissant dans le point 32
Donc les classements ne sont pas directement établis en fonction des données de trafic sur les sites. Ceux qui disent, depuis les Google Leaks, « on vous l’avait bien dit, les classements se basent sur le trafic des sites et les données de session », ont souvent en tête une vision parfois trop simple de l’algorithme de classement.
Google fait une forte utilisation des données utilisateurs pour le bon fonctionnement de son moteur. Mais il ne favorise pas forcément les sites avec le plus fort trafic en tête de ses classements : c’est naïf de penser cela, et l’observation des SERPs permet de s’apercevoir que c’est faux. L’usage de ces données se fait avant ou après la génération de la première page de résultats…
Cet article ne relève qu’une toute petite partie des informations divulguées dans cette procédure. Nous aurons l’occasion d’en révéler d’autres dans les prochaines semaines : abonnez-vous à la Newsletter pour ne rien rater.