

Historiquement, les robots d’indexation des moteurs de recherche, comme celui de Google, n’étaient pas en mesure d’explorer et d’indexer le contenu généré dynamiquement via JavaScript. Ils ne pouvaient traiter que le contenu statique du code source HTML.
Toutefois, cette réalité a évolué en raison de l’expansion des sites Web reposant fortement sur JavaScript et des frameworks tels que Angular, React et Vue.JS, ainsi que des applications à page unique (SPA) et des applications web progressives (PWA). Google a révisé son ancienne méthodologie d’exploration AJAX et traite désormais les pages web à la manière d’un navigateur moderne avant de les indexer.
Bien que Google soit généralement capable d’explorer et d’indexer la plupart des contenus JavaScript, il recommande toujours l’utilisation du rendu côté serveur ou du pré-rendu, plutôt que de se reposer sur une approche côté client. Cela est dû à la complexité du traitement de JavaScript et au fait que tous les robots d’indexation ne sont pas nécessairement en mesure de le traiter efficacement ou instantanément.
Au vu de cette évolution et des avancées des moteurs de recherche, il est crucial de pouvoir lire le DOM après l’exécution de JavaScript pour comprendre les écarts par rapport à la réponse HTML initiale lors de l’évaluation des sites web.
Les bases du SEO avec JavaScript
L’audit d’un site web requiert une compréhension de sa structure et la connaissance de l’usage ou non d’un JavaScript côté client pour les contenus ou les liens essentiels. Les frameworks JavaScript peuvent varier considérablement, et leurs impacts sur le référencement peuvent différer de ceux d’un site HTML traditionnel.
Bien que Google puisse généralement explorer et indexer JavaScript, il existe des principes fondamentaux et des limitations qu’il convient de comprendre.
- Toutes les ressources d’une page (JS, CSS, images) doivent être disponibles pour être explorées, rendues et indexées.
- Google exige toujours des URL propres et uniques pour une page et des liens dans des balises d’ancrage HTML appropriées (vous pouvez proposer un lien statique, ainsi que l’appel d’une fonction JavaScript).
- Les bots ne cliquent pas comme un utilisateur et ils ne chargent pas des événements supplémentaires après le rendu (un clic, un survol ou un défilement par exemple).
- L’instantané de la page rendue est pris lorsqu’il est établi que l’activité du réseau s’est arrêtée, ou au-delà d’un certain seuil de temps. Si le rendu d’une page prend beaucoup de temps, il risque d’être ignoré et les éléments ne seront pas vus et indexés.
- En règle générale, Google rendra toutes les pages, mais il ne mettra pas en file d’attente les pages dont la réponse HTTP initiale ou le code HTML statique contient la mention « noindex ».
- Le rendu de Google est distinct de l’indexation. Google explore d’abord le code HTML statique d’un site web et reporte le rendu jusqu’à ce qu’il dispose de ressources. Ce n’est qu’à ce moment-là qu’il découvrira le contenu et les liens supplémentaires disponibles dans le code HTML rendu. Historiquement, cela pouvait prendre une semaine, mais Google a apporté des améliorations significatives au point que le temps médian est maintenant réduit à seulement quelques secondes.
Il est essentiel de connaître ces éléments dans le cadre du référencement JavaScript.
Google conseille d’utiliser l’amélioration progressive, c’est-à-dire de construire la structure et la navigation du site en utilisant uniquement le langage HTML, puis d’améliorer l’apparence et l’interface du site à l’aide de JavaScript.
Plutôt que de s’appuyer sur le JavaScript côté client, Google recommande le rendu côté serveur, le rendu statique ou l’hydration comme solution permettant d’améliorer les performances pour les utilisateurs et les robots des moteurs de recherche.
- Le rendu côté serveur (SSR) et le pré-rendu exécutent les pages en JavaScript et fournissent une version HTML initiale de la page aux utilisateurs et aux moteurs de recherche.
- L’hydratation et le rendu hybride (également appelé « isomorphe ») sont des situations où le rendu peut être côté serveur pour le chargement initial de la page, et le code HTML est côté client pour les éléments non critiques.
De nombreux frameworks JavaScript, tels que React ou Angular, permettent nativement un rendu côté serveur et hybride.
Une autre solution consiste à utiliser le rendu dynamique. Cette solution peut s’avérer utile lorsqu’il n’est pas possible d’apporter des modifications avec du code front.
Le rendu dynamique consiste à passer d’un rendu côté client pour les utilisateurs à un contenu pré-rendu pour des agents utilisateurs spécifiques (dans ce cas, les moteurs de recherche). Cela signifie que les robots d’indexation recevront une version HTML statique de la page web pour l’indexation.
Le rendu dynamique est perçu comme une solution temporaire plutôt qu’une stratégie à long terme, étant donné qu’il n’apporte pas les bénéfices en matière d’expérience utilisateur ou de performance que certaines des autres solutions peuvent offrir.
Indexation du JavaScript
Bien que Google ait généralement la capacité d’explorer et d’indexer JavaScript, il y a d’autres facteurs à considérer. Google suit un processus d’indexation en deux étapes : initialement, il explore et indexe le code HTML statique, puis, lorsque les ressources sont disponibles, il revient pour traiter la page, explorer et indexer le contenu ainsi que les liens présents dans le code HTML traité.
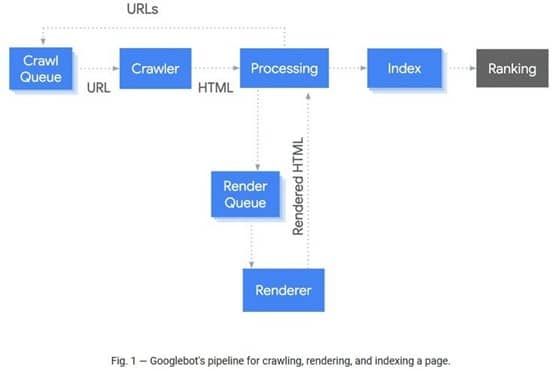
Le délai médian entre l’exploration et le rendu est de cinq secondes. Cependant, ce délai dépend de la disponibilité des ressources et être beaucoup plus long, ce qui peut poser un problème pour les sites web dépendant d’un contenu actualisé fréquemment.
Si le rendu est retardé pour une raison quelconque, les éléments de la réponse initiale, tels que les métadonnées et les éléments canoniques, peuvent être utilisés pour la page jusqu’à ce que Google réalise le rendu lorsque les ressources sont disponibles. Sauf indication contraire par une balise méta robots ou un en-tête demandant à Googlebot de ne pas indexer la page, toutes les pages seront rendues. Ainsi, la réponse HTML initiale doit être cohérente.
D’autres moteurs de recherche, comme Bing, ont du mal à rendre et à indexer le JavaScript à grande échelle. Il est assez fréquent de rencontrer des erreurs qui peuvent entraver la restitution et l’indexation du contenu.
En somme, le rendu et l’indexation comportent de nombreuses subtilités qu’il est nécessaire de garder en tête pour assurer une bonne perception du contenu par les moteurs de recherche. Essentiellement :
- L’indexation en deux phases
- Les erreurs JavaScript
- Le blocage des ressources
- Les directives dans le code HTML brut qui ordonnent aux robots de ne pas passer à la phase de rendu.
Bien que cela ne pose généralement pas de problème, s’appuyer sur le rendu côté client peut être risqué : une erreur ou un simple oubli peut avoir un impact majeur sur l’indexation des pages, avec des conséquences potentiellement coûteuses.
Il peut être relativement simple de repérer un site qui a été construit en utilisant un framework JavaScript, cependant, il peut être plus complexe d’identifier les pages, sections ou éléments et balises HTML qui sont modifiés dynamiquement grâce à JavaScript.
Cela fera l’objet d’un autre article, qui vous expliquera comment et quel outil utiliser pour identifier le JavaScript sur un site Web.
Ce contenu vous a plu ?
Inscrivez-vous gratuitement à notre newsletter et recevez chaque semaine l’actualité du SEO directement dans votre boîte email. Vous pouvez vous désabonner à tout moment !