

Depuis l’apparition de GPT d’OpenAI, des voix s’élèvent régulièrement pour dénoncer ce qu’ils considèrent comme « un vol de données », quand ce n’est pas une violation du droit d’auteur. On peut comprendre ces réactions quand on voit les IA génératives régurgiter des infos exclusives présentes sur votre site alors que vous avez consacré du temps et de l’argent pour récolter ces informations.
Sur le plan juridique, c’est un cas « gris ». Difficile de dire si c’est légal ou non.
Si un humain lit une info publiée sur un site web, et ressort l’information sans copier le texte, ou la structure d’une base de données, il peut parvenir à le faire sans violer de lois particulières.
Par contre, les LLM (les Large Language Models) font cela à une échelle telle que l’on peut se demander s’il n’y a pas violation de certains Droits Voisins. Les premiers procès ne tarderont pas à montrer dans quel sens va la jurisprudence. Sauf qu’il va falloir attendre des mois, voire des années, et peut-être une législation ad hoc pour y voir clair.
En attendant, certains se demandent si le mieux n’est pas d’interdire l’accès à vos contenus à ChatGPT.
Mais est-ce réellement possible ?
Bloquer le bot de Common Crawl : nécessaire, mais pas du tout suffisant
J’ai vu passer ces derniers jours une astuce largement partagée : bloquer CCbot via le robots.txt
CCbot, c’est le robot d’indexation du projet Common Crawl. Common Crawl est un consortium d’acteurs qui ont uni leurs efforts pour crawler une bonne partie du Word Wide Web, afin de créer un énorme corpus de pages web dans lequel vous pouvez piocher pour les utiliser dans vos projets d’analyse du web.
Pour bloquer ce bot, il suffit d’ajouter ceci dans votre robots.txt
user-agent: CCBot
Disallow: /Chez Neper, nous avions utilisé ce corpus en 2021 pour produire un modèle BERT à nous à partir de pages francophones bien ciblées, et le fine tuner. C’est pratique, et pas cher, car la licence permet d’accéder aux données gratuitement pour de la recherche.
Est-ce qu’OpenAI utilise le corpus CommonCrawl ? Oui.
Mais est-ce qu’Open AI n’utilise que ce corpus : pas du tout.
Ils utilisent de nombreux corpus différents, et ne communiquent pas sur tous.
On connait ce qui a été utilisé pour GPT3 (par contre pour GPT4 cela a été gardé secret à ma connaissance) :
- Wikipedia (bon, si vous n’êtes pas Wikipedia, tout va bien)
- Webtext2
- Books1 et Books2
CommonCrawl ne représente que 60% des contenus utilisés.
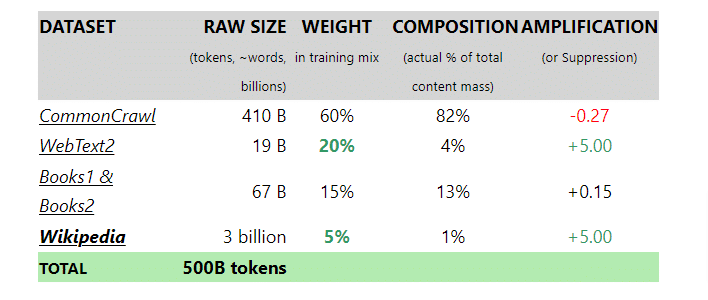
Donc bloquer CCbot est nécessaire si vous voulez « cacher » vos contenus aux IA génératives.
Mais est-ce que cela garantit qu’elles n’apparaîtront pas ? Non.
Bloquer le user agent de ChatGPT : Ok, mais est-ce vraiment malin ?
Deuxième astuce que je vois passer depuis qu’OpenAI a communiqué sur son plugin de browsing : bloquer le User-Agent ChatGPT.
Rappelons ici qu’il est effectivement possible (c’est en bêta test) depuis peu d’ajouter des plugins dans ChatGPT, plugins qui permettent d’interroger en temps réel des sources sur le web pour obtenir des réponses avec des données « fraiches ».
Et lorsque le plugin va chercher des données, il utilise un browser headless dont le User Agent est : ChatGPT.
Donc oui on peut bloquer ChatGPT à coup sûr dans ce cas d’utilisation :
user-agent: ChatGPT-User
Disallow: /Mais est-ce réellement toujours malin ?
Car cela signifie que vous empêchez ChatGPT de rendre votre contenu visible dans un contexte où il montrera la source d’info. Bref un cas dans lequel il peut y avoir du trafic ou de la visibilité offerte par ChatGPT.
Donc réfléchissez bien à l’intérêt réel du blocage.
Ce que vous n’arriverez pas à bloquer, sauf à bloquer TOUS les bots
Bon, reste qu’aucune solution n’existe pour les autres corpus. Dans certains cas, les corpus sont constitués sans respecter le robots.txt, car rien ne les y oblige légalement. Et on ne sait pas exactement ce qui a été utilisé pour fabriquer la plupart des LLM.
Donc, impossible aujourd’hui d’empêcher les IA génératives d’aspirer votre contenu (ce qu’elles ont déjà probablement fait depuis des mois).
La seule solution relativement efficace serait de bloquer le crawl de tous les robots avec des solutions comme Datadome ou ses concurrents. Mais ces solutions ont un prix.
Et, mal paramétrées, ces solutions bloqueront aussi les bots utiles…
Donc attention à ne pas céder à la manie de bloquer CCbot ou le bot ChatGPT : cela ne résout rien, et cela peut engendrer des effets de bord non désirés.
Ce contenu vous a plu ?
Inscrivez-vous gratuitement à notre newsletter et recevez chaque semaine l’actualité du SEO directement dans votre boîte email. Vous pouvez vous désabonner à tout moment !