
Le fichier robots.txt est un fichier texte placé à la racine d’un site Web et qui peut être consulté par les robots d’exploration ou les « bots » des moteurs de recherche. Il est utilisé pour déterminer les pages à indexer ou à éviter sur un site Web.
Ce qu’est le fichier robots.txt
Le fichier robots.txt est utilisé pour donner des instructions aux robots d’exploration sur la façon de naviguer sur un site Web. Il est souvent utilisé pour empêcher les robots d’indexer des pages qui ne sont pas destinées à être indexées, telles que les pages de maintenance, les pages de test ou les pages de connexion. Il peut également être utilisé pour limiter l’accès à certaines parties d’un site Web, en particulier lorsqu’il s’agit de sites Web qui contiennent des informations confidentielles.
Pour créer un fichier robots.txt, il suffit de créer un fichier texte nommé « robots.txt » et de le placer à la racine du site Web. Le contenu du fichier doit suivre une syntaxe spécifique pour que les robots d’exploration puissent l’interpréter correctement. Vous pouvez par ailleurs utiliser des outils en ligne pour vérifier si votre fichier robots.txt contient des erreurs.
En résumé, le fichier robots.txt est un outil important pour les propriétaires de sites Web qui souhaitent contrôler les pages à indexer ou à éviter. Il peut aider à améliorer la visibilité et le classement d’un site Web dans les moteurs de recherche. Je dirais même que c’est le premier fichier à aller consulter quand on est référenceur.
Généralités sur les règles de syntaxe du fichier robots.txt
Les règles de syntaxe pour écrire un fichier robots.txt sont assez simples et suivent une structure de base. En voici les éléments clés :
- Le fichier doit être nommé « robots.txt » et placé à la racine du site Web. Par exemple https://www.monsite.com/robots.txt
- Les instructions pour les robots d’exploration sont définies par des « directives » qui indiquent ce que les robots sont autorisés à explorer et ce qu’ils doivent ignorer sur le site Web.
- Les directives sont précédées du nom de l’agent utilisateur, qui spécifie le robot d’exploration concerné, suivi de deux points (:). Par exemple, « User-agent: Googlebot ». Dans le cas où aucun User-agent est spécifié, et que touts les bots sont concernés, la syntaxe à utiliser comporte un joker et elle est la suivante : Usant-agent: *
- Les directives commencent par « Allow » ou « Disallow » suivi d’une URL du site Web. Par exemple, « Disallow: /admin » empêchera les robots d’explorer les pages du site Web qui contiennent « admin » dans l’URL.
- Les directives peuvent également inclure « Sitemap » pour indiquer l’emplacement d’un sitemap XML contenant des informations sur les pages à explorer. Cette ligne est la dernière ligne du fichier robots.txt.
Il est important de noter que chaque robot d’exploration peut avoir une syntaxe légèrement différente pour interpréter les directives du fichier robots.txt. Par conséquent, il est important de bien comprendre la syntaxe et de tester le fichier pour s’assurer qu’il est correctement interprété par les robots d’exploration [1].
La création d’un fichier robots.txt, avec un peu de pratique et de compréhension de la syntaxe de base, est une opération simple, mais combien importante. Il est essentiel de bien comprendre les directives pour éviter d’empêcher les robots d’explorer des pages importantes du site Web.
Une norme
Pour s’assurer d’un minimum de compatibilité entre les différents moteurs de recherche pour un même fichier robots.txt, une norme a été mise en place.
Vous trouverez cette norme ici : https://www.robotstxt.org/orig.html. Cette norme qui date de 1994 a été reprise pas l’essentiel des bots des moteurs de recherche, avec des petites variantes et des évolutions au fil du temps.
En fonction du type de fichier, les effets du fichier robots.txt diffèrent. Pour un fichier ressource (CSS, scripts, etc.), en bloquer l’accès pourra affecter de façon significative le fonctionnement et le chargement d’une page, ce qui n’est pas recommandé par Google par exemple. Google n’a aucune difficulté à reconnaitre ce type de ressource et il peut en avoir besoin pour analyser correctement les pages dépendantes de ces ressources.
Pour un fichier multimédia, vous pourrez en limiter l’affichage dans les résultats de recherche avec un fichier robots.txt mais ce n’est pas la bonne pratique en SEO, ni la plus efficace. Il est, en effet, préférable, dans ce cas d’utiliser une balise meta robots « noindex » sur la page support du fichier concerné ou d’indiquer une date d’expiration passée dans les données structurées via la propriété <expires>. Cette alternative permet aux moteurs de recherche d’indexer le reste de la page contrairement à la première solution proposée.
Enfin, pour une page Web, qui est le cas le plus courant (HTML, PDF, etc.) – retrouvez ici la liste des types de fichiers indexables par Google – vous pouvez contrôler facilement le trafic d’exploration.
Remarque : n’utilisez jamais le fichier robots.txt pour empêcher l’affichage d’une page dans les SERP ! En effet, si cette page a des liens entrants depuis d’autres sources qui sont elles-mêmes indexées, Les bots pourront découvrir votre page et l’indexer sans y avoir accès directement ! Il s’agit d’une erreur courante. La solution est d’utiliser une balise meta robots « noindex » ou encore une directive X-Robots-Tag noindex.
Des limites
Tout n’est pas faisable avec un fichier robots.txt en matière de contrôle du trafic d’indexation. Par ailleurs, il ne faut négliger non plus que parfois une combinaison de plusieurs règles d’exploration peut créer des conflits et donc être totalement inefficace.
- Les règles ne sont pas toutes compatibles avec tous les robots des différents moteurs.
- Les robots des moteurs de recherche peuvent avoir une interprétation différente d’une même syntaxe.
- Le blocage n’est pas absolu dans le cas ou une page dont l’exploration est interdite, est linkée par une autre source.
La syntaxe reconnue par Google
Google a publié en septembre 2022 la RFC 9309 Robots Exclusion Proptocol qui spécifie et étend la méthode « Robots Exclusion Protocol » définie à l’origine par Martijn Koster en 1994 (voir le lien dans le paragraphe Une norme). La RCF 9309 a pour but de permettre aux propriétaires de services de contrôler la manière dont le contenu servi par leurs sites peut être accédé, le cas échéant, par les crawlers des moteurs de recherche. Plus précisément, il ajoute un langage de définition pour le protocole, des instructions pour la gestion des erreurs et des instructions pour la mise en cache.
Google accepte les champs suivants :
- User-agent : identifie le robot d’exploration auquel les règles s’appliquent.
- Allow : chemin d’URL à explorer.
- Disallow : chemin d’URL à ne pas explorer.
- Sitemap : URL complète d’un sitemap.
Chaque règle Allow ou Disllow doit être suivi par un chemin (path) relatif. Par exemple :
Disallow: /admin/La règle sitemap doit être suivi par un chemin absolu. Par exemple :
Sitemap: https://www.domain.com/sitemap.xmlCorrespondance d’URL en fonction des valeurs des chemins pour Google
Google utilise la valeur du chemin d’accès dans les règles allow et disallow pour déterminer si une règle s’applique à une URL spécifique d’un site. Pour ce faire, la règle est comparée au composant du chemin d’URL que le robot d’exploration tente de suivre. Les caractères ASCII non encodés en 7 bits dans un chemin d’accès peuvent être inclus sous forme de caractères UTF-8 ou de caractères d’échappement encodés en UTF-8 sous forme de pourcentage conformément à la RFC 3986.
Seuls certains caractères génériques pour les valeurs de chemin sont compatibles avec Google, Bing et les autres moteurs de recherche connus. Ces caractères génériques sont les suivants :
*désigne 0 ou plusieurs instances d’un caractère valide.$désigne la fin de l’URL.
Le tableau suivant montre comment les différents caractères génériques affectent l’analyse :
| Exemples de correspondances de chemins | |
|---|---|
/ | Correspond à l’URL racine et à toute URL de niveau inférieur. |
/ | Équivaut à /. Le caractère générique de fin est ignoré. |
/ | Ne correspond qu’à la racine. Toute URL de niveau inférieur peut être explorée. |
/ | Correspond à tout chemin commençant par /fish. Notez que la correspondance est sensible à la casse.Correspondances : /fish/fish.html/fish/salmon.html/fishheads/fishheads/yummy.html/fish.php?id=anythingPas de correspondance : /Fish.asp/catfish/?id=fish/desert/fish |
/ | Équivaut à /fish. Le caractère générique de fin est ignoré.Correspondances : /fish/fish.html/fish/salmon.html/fishheads/fishheads/yummy.html/fish.php?id=anythingPas de correspondance : /Fish.asp/catfish/?id=fish/desert/fish |
/ | Correspond à tous les éléments du dossier /fish/.Correspondances : /fish//fish/?id=anything/fish/salmon.htmPas de correspondance : /fish/fish.html/animals/fish//Fish/Salmon.asp |
/ | Correspond à tout chemin contenant .php.Correspondances : /index.php/filename.php/folder/filename.php/folder/filename.php?parameters/folder/any.php.file.html/filename.php/Pas de correspondance : / (même si cela correspond à /index.php)/windows.PHP |
/ | Correspond à tout chemin se terminant par .php.Correspondances : /filename.php/folder/filename.phpPas de correspondance : /filename.php?parameters/filename.php//filename.php5/windows.PHP |
/ | Correspond à tout chemin contenant /fish et .php, dans cet ordre.Correspondances : /fish.php/fishheads/catfish.php?parametersPas de correspondance : /Fish.PHP |
Les User-agents de Google
Google utilise de nombreux bots (user-agent) qui ne respectent pas tous les règle du fichier robots.txt. En voici la liste.
Source : https://developers.google.com/search/docs/crawling-indexing/overview-google-crawlers?hl=fr
Attention : La chaîne user-agent peut être falsifiée. Découvrez comment vérifier si un visiteur est un robot d’exploration Google.
| Robots d’exploration | |
|---|---|
| APIs-Google | Jeton user-agentAPIs-GoogleChaîne user-agent complète APIs-Google (+https://developers.google.com/webmasters/APIs-Google.html) |
| AdsBot Mobile Web Android | AdsBot Mobile Web Android ignore le caractère générique *.Vérifie la qualité des annonces sur les pages Web pour Android. Jeton user-agent AdsBot-Google-MobileChaîne user-agent complète Mozilla/5.0 (Linux; Android 5.0; SM-G920A) AppleWebKit (KHTML, like Gecko) Chrome Mobile Safari (compatible; AdsBot-Google-Mobile; +http://www.google.com/mobile/adsbot.html) |
| AdsBot Mobile Web | AdsBot Mobile Web ignore le caractère générique *.Vérifie la qualité des annonces sur les pages Web pour iPhone. Jeton user-agent AdsBot-Google-MobileChaîne user-agent complète Mozilla/5.0 (iPhone; CPU iPhone OS 14_7_1 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.1.2 Mobile/15E148 Safari/604.1 (compatible; AdsBot-Google-Mobile; +http://www.google.com/mobile/adsbot.html) |
| AdsBot | AdsBot ignore le caractère générique *.Vérifie la qualité des annonces sur les pages Web pour ordinateur. Jeton user-agent AdsBot-GoogleChaîne user-agent complète AdsBot-Google (+http://www.google.com/adsbot.html) |
| AdSense | Jeton user-agentMediapartners-GoogleChaîne user-agent complète Mediapartners-Google |
| Googlebot Image | Jetons user-agentGooglebot-ImageGooglebotChaîne user-agent complète Googlebot-Image/1.0 |
| Googlebot-News | Jetons user-agentGooglebot-NewsGooglebotChaîne user-agent complète Le user-agent Googlebot-News utilise les différentes chaînes de user-agents Googlebot. |
| Centre pour les éditeurs de Google | Attention : Le Centre pour les éditeurs de Google ne respecte pas les règles du fichier robots.txt. Récupère et traite les flux que les éditeurs ont explicitement fournis via le Centre pour les éditeurs de Google à utiliser sur les pages de destination de Google Actualités. Jeton user-agent GoogleProducerChaîne user-agent complète GoogleProducer; (+http://goo.gl/7y4SX) |
| Googlebot Video | Jetons user-agentGooglebot-VideoGooglebotChaîne user-agent complète Googlebot-Video/1.0 |
| Googlebot pour ordinateur | Jeton user-agentGooglebotChaînes user-agent complètes Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Googlebot/2.1; +http://www.google.com/bot.html) Chrome/W.X.Y.Z Safari/537.36Googlebot/2.1 (+http://www.google.com/bot.html) |
| Googlebot pour smartphone | Jeton user-agentGooglebotChaîne user-agent complète Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/W.X.Y.Z Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) |
| Mobile AdSense | Jeton user-agentMediapartners-GoogleChaîne user-agent complète (Various mobile device types) (compatible; Mediapartners-Google/2.1; +http://www.google.com/bot.html) |
| Mobile Apps Android | Mobile Apps Android ignore le caractère générique *.Vérifie la qualité des annonces sur les pages d’applications Android. Respecte les règles des robots AdsBot-Google.Jeton user-agent AdsBot-Google-Mobile-AppsChaîne user-agent complète AdsBot-Google-Mobile-Apps |
| Feedfetcher | Attention : Feedfetcher ne respecte pas les règles du fichier robots.txt. Jeton user-agent FeedFetcher-GoogleChaîne user-agent complète FeedFetcher-Google; (+http://www.google.com/feedfetcher.html) |
| Google Read Aloud | Attention : Google Read Aloud ne respecte pas les règles du fichier robots.txt. Jeton user-agent Google-Read-AloudChaînes user-agent complètes Agents actuels : Agent pour ordinateur : Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.118 Safari/537.36 (compatible; Google-Read-Aloud; +https://developers.google.com/search/docs/crawling-indexing/overview-google-crawlers)Agent mobile : Mozilla/5.0 (Linux; Android 7.0; SM-G930V Build/NRD90M) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.125 Mobile Safari/537.36 (compatible; Google-Read-Aloud; +https://developers.google.com/search/docs/crawling-indexing/overview-google-crawlers)Ancien agent (obsolète) : google-speakr |
| Google Favicon | Attention : Google Favicon ignore les règles du fichier robots.txt pour les requêtes lancées par l’utilisateur. Jeton user-agent Googlebot-ImageGooglebotChaîne user-agent complète Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.75 Safari/537.36 Google Favicon |
| Google StoreBot | Jeton user-agentStorebot-GoogleChaînes user-agent complètes Agent pour ordinateur : Mozilla/5.0 (X11; Linux x86_64; Storebot-Google/1.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36Agent mobile : Mozilla/5.0 (Linux; Android 8.0; Pixel 2 Build/OPD3.170816.012; Storebot-Google/1.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Mobile Safari/537.36 |
| Google Site Verifier | Attention : Google Site Verifier ignore les règles du fichier robots.txt. Jeton user-agen t Google-Site-VerificationChaîne user-agent complète Mozilla/5.0 (compatible; Google-Site-Verification/1.0) |
Quelques erreurs fréquentes qui peuvent avoir de lourdes conséquences
Position des commentaires
Il est tout à fait possible de commenter son fichier robots.txt pour permettre à l’ensemble des intervenants de comprendre les différentes directives et leur portée. Cela est très utile sur les fichiers robots.txt particulièrement longs et complexes.
L’erreur à ne pas commettre est celle représentée ci-dessous :
User-agent: Googlebot
# Les directives ne s'adressent qu'a Google !
Disallow: /private/
Disallow: /upload/
#Les autres directives qui s'adressent à tous les bots
User-agent: *
Disallow: /admin/L’erreur vient du fait que dans la première partie de l’exemple donné, on retrouve les commentaires entre l’User-agent et les directives associées à ce bloc. C’est une mauvaise pratique qui peut rendre inefficace la spécification du bot pour le bloc de directives qui suit.
La seconde partie est la bonne façon de faire.
Le Retour-Chariot
Selon la plateforme utilisée / l’outil utilisé pour générer le retour chariot dans la création / mise à jour de votre fichier robots.txt, il est possible que le caractère utilisé ne soit pas correctement pris en compte. Conséquence, les directives se masquent les unes les autres, rendant le fichier inefficace dans sa finalité.
Pour être certain que les sauts de ligne, RC et autres caractères 13, 20, 00, etc. il est nécessaire d’utiliser une application, par exemple Notepad++ qui permet de les afficher clairement et sans ambiguïté.
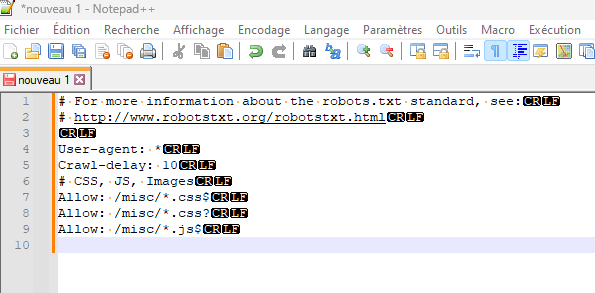
L’illustration ci-dessus montre un exemple qui répond aux deux cas évoqués.
N’hésitez pas à me poser vos questions sur le fichier robots.txt, je vous répondrais avec plaisir.
Ce contenu vous a plu ?
Inscrivez-vous gratuitement à notre newsletter et recevez chaque semaine l’actualité du SEO directement dans votre boîte email. Vous pouvez vous désabonner à tout moment !
Des articles toujours aussi clairs et complets 🙏
Merci à l’quipe
Avec plaisir Jean.
Excellente journée.