
J’ai déjà lu trois articles francophones (dont un qui a été publié sur le Journal du Net) qui popularisent une notion soit disant nouvelle et soit disant importante en SEO : le « seuil de qualité« . Pas « seuils de qualité » au pluriel, LE seuil de qualité. Une notion attribuée à un expert Turc, Koray Tuğberk GÜBÜR
Bon, je ne jette pas la pierre à ceux qui ont repris et commenté les affirmations de Koray Tuğberk GÜBÜR, c’est un expert dans le mille feuilles argumentatif et dans l’art de cacher un discours pseudo scientifique sous un tas de données et de résultats de tests qui ne prouvent rien.
Je vous laisse prendre connaissance de l’article de Koray GÜBÜR sur oncrawl.com qui développe le concept.
https://www.oncrawl.com/technical-seo/importance-quality-thresholds-predictive-ranking/
Et bien, nous allons voir que c’est un non sujet. Et qu’il est inutile de créer un nouveau nom pour un comportement attribué à Google qui s’avère ne pas coller à la réalité. Une réalité qui est plus complexe et plus nuancée.
Vous faites du SEO : vous avez besoin d’un radar à Bullshit
En règle générale, je ne passe pas mon temps à débunker toutes les cuistreries qui s’écrivent à propos du SEO : je n’aurai plus assez de temps pour mes clients.
C’est la fameuse loi de Brandolini : « la quantité d’énergie nécessaire pour réfuter des idioties est supérieure d’un ordre de grandeur à celle nécessaire pour les produire ».
Mais quand je peux étouffer dans l’oeuf la naissance d’un nouveau mythe SEO, je ne m’en prive pas. Il vaut mieux le faire avant que cela devienne parole d’évangile au sein de la communauté, c’est ce qui coûte le moins d’énergie.
Je l’ai fait pour la première fois en 2006 à propos du Latent Semantic Indexing (une invention de nos collègues US), ou plus récemment à propos de WF*IDF (une invention de nos collègues allemand) ou des Topic Clusters version Hubspot/Neil Patel (une invention US).
Remarque : en France, on est pas les derniers à inventer à des concepts ou des méthodes moisies.
Bon, je vous donne déjà un truc pour identifier les sujets suspects : quand un concept en SEO ne sort pas d’un pays, c’est un indice que c’est peut être une ânerie. Ok, cela peut vouloir dire aussi que le reste du monde n’en a pas encore entendu parler, mais rasoir d’Occkham, l’explication la plus probable c’est que cela ne franchit pas les frontières parce que l’argumentation derrière ne tient pas debout.
Et là, qui parle de « quality threshold » à part Koray Tuğberk GÜBÜR : personne. Y compris dans les communautés SEO et allemandes qui sont ses principales chambres d’écho. D’autres parlent de seuils de qualité appliqués potentiellement dans différents endroits du moteur de recherche Google, et donc de seuils de qualité qui ont une autre définition.
C’est quoi ce prétendu « Seuil de Qualité »
Selon les exégètes de Koray, il existerait un « seuil » à partir duquel un certain « score de qualité » permettrait à une page web de figurer dans l’index primaire de Google (par opposition à l’index supplémentaire).
Bon déjà, premier problème : l’architecture de Google ne comporte plus cette dichotomie entre un index primaire et supplémentaire (ou secondaire) depuis… douze ans.
Je pourrais m’arrêter là et dire : fin de l’histoire.
Mais comme je suis honnête intellectuellement, je dois quand même préciser que c’est une
Car si les deux index n’existent plus depuis longtemps, cela ne signifie pas que la raison qui justifiait leur existence a disparu. Et Google a probablement basculé sur quelque chose qui respectait la même logique.
Moins une page à de chances de se positionner en tête de résultats sur une requête, moins c’est utile de stocker tous les scores pour cette page
En effet, tous ceux qui construisent des moteurs de recherche sont obsédés par les contraintes qui pèsent sur les performances. Quand il s’agit d’être capable de produire une page de résultats en une poignée de millisecondes, la moindre économie dans les données à calculer ou à traiter est bonne à prendre.
Donc c’est une pratique assez universelle de créer des bases de données où en face de chaque entrée de la base de données, on stocke plus d’infos (de scores) pour les pages qui vont apparaître dans le top 30 que pour celles qui vont apparaître dans le top 100.
Bref, le moteur dispose de quoi classer finement le top 30, le classement est un peu plus grossier sur les pages 4 à 10, et au delà, c’est du grand n’importe quoi.
La probabilité que Google continue d’utiliser cette astuce en 2022 est grande…
Mais cela signifie qu’il faut « prédire » lors de l’indexation quelles pages sont susceptibles de sortir dans le top des positions. Dans les débuts de Google, les documents étaient préordonnés pour une entrée dans l’index en fonction de leur score TF*iDF et peut-être en combinaison avec leur Pagerank pour le top 30.
Ces mécanismes sont décrits ici :
Indexing The World Wide Web : the journey so far
https://static.googleusercontent.com/media/research.google.com/fr//pubs/archive/37043.pdf
Ah tiens : il y’a bien ici une notion de « seuil », mais ce seuil ne concerne pas un score de qualité.
Ou trouve-t’on ces notions de seuil de qualité dans l’algorithme de Google.
Dans la pratique on trouve des seuils un peu partout dans l’algorithme de Google.
Par exemple, il existe un score associé à des seuils qui détermine si une page va être crawlée et indexée. Ce score s’appelait « Crawl score », maintenant Google parle de « page importance ».
Ce système est décrit dans un brevet :
https://patents.justia.com/patent/20170091324
Mais comme tous les brevets, on ne sait pas vraiment si Google utilise exactement ce système : on sait juste que c’est une pratique courante dans les moteurs de recherche.
Par ailleurs, Google utilise des « classifieurs » dans plusieurs endroits dans l’algorithme. En intelligence artificielle, un classifieur est une fonction à base d’IA qui va être capable de « classer » un item dans une case. Par exemple, décider si un contenu a un score suffisant pour ne pas déclencher la mise en oeuvre d’un filtre.
Ce type d’approche existe dans Panda, Penguin ou la HCU update. On trouve également ce type d’approche dans les outils de détection du webspam. Ce qui est intéressant dans ces quatre cas, c’est que l’analyse porte à chaque fois sur un aspect différent de la qualité.
Y’a-t’il une notion de « seuil de qualité » à chaque fois ?
Pour Panda et Penguin, on a bien une notion de seuil, pas forcément pour la HCU.
Donc attention, il ne faut pas voir des seuils partout. Lorsqu’on ne voit pas d’effet de seuil, c’est peut-être parce qu’il n’y a pas de seuil. Et lorsqu’on croit voir un effet seuil, c’est peut-être explicable par un changement causé par autre chose que le franchissement d’un seuil.
Le « predictive ranking » et la qualité
Dans le discours sur LE seuil de qualité (notez que Koray Tuğberk GÜBÜR alterne les références au « seuil de qualité » au pluriel et au singulier), il est fait beaucoup fait référence au « predictive ranking ».
Déjà, il ne faut pas confondre le « predictive ranking » et le « predictive crawling ». Le predictive crawling est une approche qui a été décrite dans cet article :
Et tiens, il y’a bien une notion de seuil. Mais il s’agit d’une méthode pour rendre l’exploration par Googlebot plus efficace.
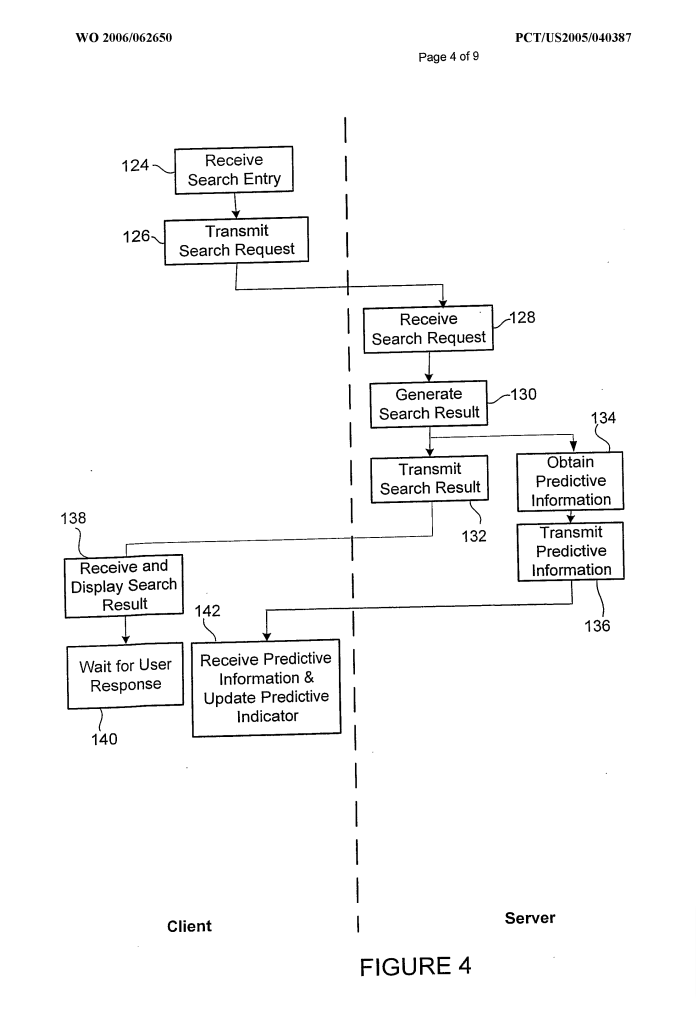
Le « predictive ranking » est une notion qui apparait dans ce brevet de Google :
https://patents.google.com/patent/WO2006062650A1
Comme d’habitude, nos amis aux USA brevètent toutes leurs idées, et cela n’est pas parce que Google a déposé ce brevet que c’est utilisé.
L’idée ici est de « prédire » les documents qui vont être sélectionnés par un utilisateur pour les précharger afin de fluidifier l’expérience de recherche. C’est particulièrement approprié pour des usages mobiles avec une connexion dégradée.
Autant vous dire qu’il n’y a pas de rapport entre ce brevet, la notion de qualité, et a fortiori la notion de « seuil de qualité ».
Qu’est-ce que cela fait ici dans cette histoire alors ?
Je m’interroge évidemment, je pense qu’il s’agit d’une confusion avec d’autres concepts imaginés pour améliorer les moteurs de recherche. Comme le neural matching, ou les approches de type « learning to rank ». Mais leur exploitation dans Google est plutôt limitée.
Conclusion : des seuils oui, mais LE seuil de qualité n’est pas un concept actionnable en SEO
Bon, en conclusion :
- il y’a bien des « seuils » utilisés dans plusieurs endroits du fonctionnement de Google.
- Certains de ces seuils tournent autour de la notion de qualité, mais ils sont reliés à plusieurs scores. J’en ai cité certains, il y’en a d’autres connus, et sans doutes d’autres sur lesquels Google n’a jamais communiqué.
- Par conséquent, on a pas d’effet de seuil uniques, mais plusieurs effets de seuils dont les effets peuvent se combiner / se compenser / se renforcer
Donc cette notion de « seuil de qualité » unique et universel ne définit aucun indicateur réel et tangible. Donc rien qui puisse être mesuré utilement ou testé.
Et surtout, cela ne définit rien d’utile pour définir des actions efficaces en SEO.
C’est différent si on descend à un niveau de granularité plus fin, où là on peut définir des recommandations plus utiles et directement efficaces.
Donc, ne cherchez pas à optimiser vos pages en fonction de cette notion floue de seuil de qualité.
Et vous pouvez même oublier le concept : il n’y a pas UN seuil de qualité en SEO. Mais plusieurs.
Ce contenu vous a plu ?
Inscrivez-vous gratuitement à notre newsletter et recevez chaque semaine l’actualité du SEO directement dans votre boîte email. Vous pouvez vous désabonner à tout moment !