
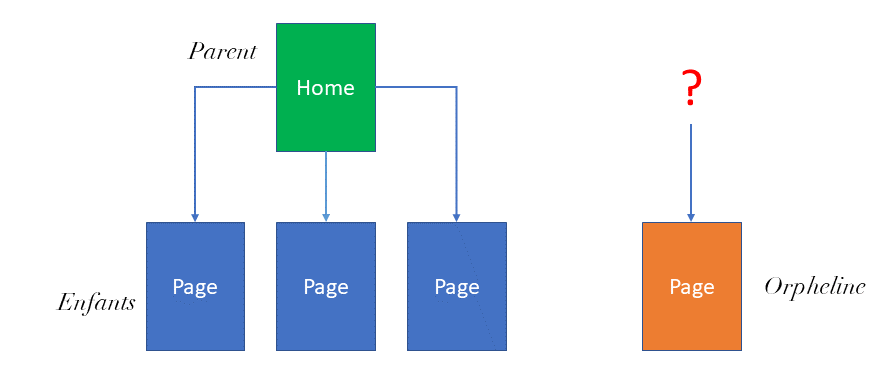
Dès que l’on travaille l’optimisation de sites comportant des milliers de pages, on constate le phénomène suivant :
- certaines urls qui ne font pas partie de l’arborescence du site sont crawlées par Google. Parfois ces urls sont indexées et captent même un peu de trafic. Ces urls sont appelées « pages orphelines » en jargon SEO.
- et certaines urls, qui elles font partie de l’arborescence du site, sont ignorées par Google. C’est un autre sujet, que nous aborderons la semaine prochaine (« Comment faire pour que toutes mes pages soient indexées »).
Les urls censées faire partie de l’arborescence du site sont identifiables par un crawler, paramétré comme Googlebot. Les urls crawlées par Googlebot sont identifiables dans les logs serveurs (il suffit d’analyser les hits pour lesquels le « user agent » est Googlebot).
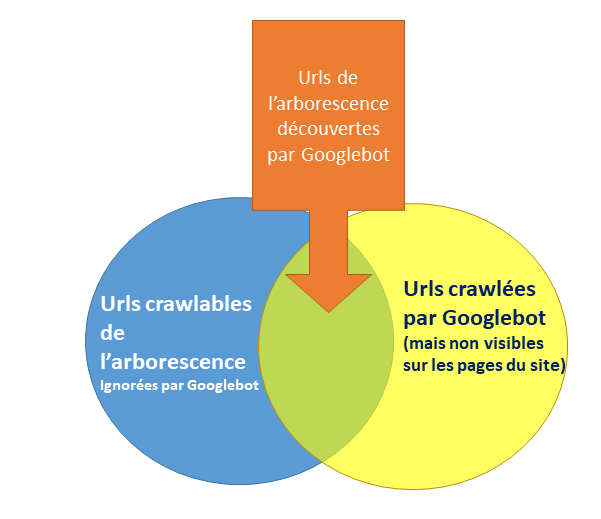
Dans ce premier article, nous allons nous intéresser plus spécialement au cas des pages orphelines.
DEFINITION DES PAGES ORPHELINES
Le terme « page orpheline » dans son acception moderne a été inventé dans le cadre des analyses combinées logs et crawl dans au milieu de la décennie 2010. Sa définition est simple : une page est dite « orpheline » si elle n’a pas de parent dans l’arborescence d’un site donné. Elle peut pointer vers une page parente (elle peut comporter un fil d’ariane/breadcrumb ou toute autre forme de lien remontant) ou non. Mais aucune page ne fait un lien vers cette page !
Dans tous les cas, ces pages répondent un code 200. Sinon ce ne sont pas des vraies pages orphelines.
Jadis, on désignait comme page orpheline des pages qui n’étaient pas reliées à l’arborescence et pourtant existaient et répondaient 200 quand on appelait leur url.
Aujourd’hui, cela désigne plutôt les cas de pages qui répondent 200, sont crawlées par Googlebot mais n’ont pas de parent dans l’arboresence du site.
Pourquoi ce glissement de sens ? Tout simplement parce que les pages orphelines stricto sensu sont difficiles à détecter. C’était possible au début du web lorsque les pages HTML étaient statiques et stockées physiquement : on pouvait identifier des pages dans le répertoire du site qui n’étaient pas liées. Mais aujourd’hui les pages sont dynamiques, il est assez facile de trouver des syntaxes d’urls qui génèrent des pages orphelines dont l’url n’est pas dans l’arborescence (essayez de taper www.domaine.com/nimportekoi ou de changer un mot clé dans une url sans changer l’identifiant numérique et vous aurez (trop) souvent un code 200 en réponse).
L’enjeu pour le SEO ce n’est pas de détecter l’intégralité de ces cas, mais juste ceux qui sont problématiques. Donc les urls crawlées par Googlebot, qui répondent un code 200, sans figurer parmi les urls linkées dans l’arborescence.
Les quatre types de pages orphelines
Parmi les pages orphelines crawlées par Googlebot, il faut distinguer quatre cas différents, et qu’il faut traiter différemment
- les pages « faussement orphelines »
- les pages « orphelines parasites »
- les pages orphelines actives
- les pages oubliées inactives
Les pages « faussement orphelines »
On les appelle « faussement orphelines » car elles ont une syntaxe d’url qui est juste une variante de la syntaxe qui figure véritablement dans l’arborescence :
- par exemple un paramètre supplémentaire dans l’url,
- ou une syntaxe brute correspondant à une syntaxe réécrite sur le site.
Nous sommes en réalité confrontés ici à des cas d’url dupliquées (de la poussière, DUST en anglais : duplicate urls same text).
Et dans la majorité des cas, ces syntaxes sont certes crawlées par Googlebot, mais canonicalisées correctement avec la syntaxe figurant sur le site. Par exemple, Google a compris que le paramètre dans l’url ne change pas le contenu de la page et l’ignore. Il indexera l’url sans paramètres et tous les scores de l’url orphelines seront agrégés avec ceux de l’url indexée.
Bref, ces pages sont « faussement orphelines ».
Attention : si ces urls reçoivent du trafic SEO, alors elles deviennent des pages orphelines actives => voir plus loin
Faut-il traiter ces pages ?
Tout dépend de la volumétrie et du budget de crawl dépensé pour les explorer.
Si le volume de crawl sur ces urls est important, cela peut être une bonne idée :
- de bloquer ces syntaxes dans le robots.txt (si possible).
- de rediriger ces urls vers la syntaxe canonique (toujours préférer cette solution si les urls orphelines reçoivent des backlinks) avec une redirection 301
- ou à défaut, d’ajouter des link rel canonicals vers la syntaxe canonique
Sinon, on peut laisser ces urls tranquilles, Google gère la situation.
Par contre, si vous testez l’indexation de syntaxes de pages orphelines, vous vous rendrez compte que certains types de syntaxe sont réellement indexés. Ces pages appartiennent aux catégories décrites ci-après.
Les pages orphelines parasites
Dans la plupart des cas (les pages orphelines actives ou oubliées sont des exceptions, voir plus loin) les syntaxes de pages orphelines crawlées représentent un problème. Ces pages sont souvent des doublons d’urls existantes, ou des pages vides, ou des pages sans intérêt.
Si elles n’ont pas d’équivalent dans l’arborescence, on a affaire à des pages orphelines dites « parasites » : il convient :
- soit de renvoyer un code 404 (cette url n’ayant rien à faire dans l’arborescence, ni dans la liste des pages crawlables et indexables)
- soit de bloquer la syntaxe par une directive dans le robots.txt
Lorsque les urls des pages orphelines sont indexées, pensez à les désindexer (via la GSC, ou une balise meta noindex) avant de bloquer le crawl, sinon elles risquent de rester dans l’index pendant des mois.
Les pages orphelines actives
Une page orpheline active est une page orpheline qui reçoit du trafic SEO !
Cela sous-entend :
- qu’à l’appel de cette url, Googlebot reçoit un code 200
- que l’url est crawlable, indexable, et indexée
- et qu’elle est même suffisamment visible dans les pages de résultat de Google pour capter des clics d’internautes
- mais qu’elle est introuvable sur les pages de votre site !
C’est clairement une anomalie qu’il faut traiter.
Premier cas d’urls orphelines actives : les urls dupliquées mal canonicalisées
Parmi les cas de pages orphelines actives, on a des cas d’urls dupliquées (avec des paramètres par exemple) pour lesquels Google choisit comme version canonique une autre version que celle disponible sur les pages du site. Il y’a toujours une bonne raison qui explique ce comportement :
- incohérences dans les signaux identifiant la version canonique : la version de la syntaxe « hors arborescence » est dans le sitemap, la balise canonique a une syntaxe erronée, est implémentée à l’envers, contredit le hreflang, ou une redirection, etc.
- Google choisit l’url orpheline parce qu’elle a de meilleurs scores : cela arrive fréquemment quand des backlinks pointent vers la version hors arborescence
Dans les deux cas, il faut aider Google à indexer une seule version de l’url dupliquée, et en priorité celle qui est affichée sur le site. Les correctifs doivent aboutir également à agréger les scores des deux urls, il ne faut pas bloquer le crawl de la syntaxe hors arborescence.
On peut y parvenir :
- en redirigeant avec une redirection 301 la syntaxe hors arborescence vers la syntaxe dans l’arborescence (cela marche à tous les coups)
- en ajoutant une balise link rel canonical de la syntaxe hors arborescence vers celle située dans l’arborescence (résultat non garanti, le comportement de Google ne changera que si vous remplacez des signaux ambigus par des signaux clairs)
Deuxième cas d’urls orphelines actives : les pages non maillées
Dans certains cas, les pages orphelines actives ne correspondent pas à des doublons : il s’agit juste d’urls non maillées dans l’arborescence du site. Ce sont de vraies pages orphelines !
Si ces pages ont été oubliées dans le maillage : il faut les relier aux pages existantes.
On a toujours intérêt à traiter ce genre de page car si elle se positionne sans être maillée sur le site, elle risque de gagner des positions une fois rattachée à l’arborescence.
Les « vieilles pages » orphelines mais actives
Il peut arriver que ces pages orphelines actives soient de vieilles pages, dont on ne voulait plus.
Comme Google en connait l’url, il continue à les crawler, et si elles répondent 200 et sont indexables, elles peuvent continuer de figurer dans les pages de résultats très longtemps.
Si ces vieilles pages génèrent encore du trafic, cela signifie que vous avez intérêt à réfléchir à un moyen de les réintégrer sur le site actuel, quitte à réactualiser leur contenu et leur design.
Les pages orphelines « oubliées » inactives
On vient de voir que des pages non maillées pouvaient exister, et être actives.
Mais la majorité de ces pages sont souvent inactives : elles sont peut-être indexées, sans capter de trafic, parce qu’elles apparaissent au delà de la 30e position sur des requêtes. Ou elles peuvent être ignorées par Google.
Si des urls non maillées sont connues de Google et crawlées, ces cas de pages orphelines seront ignorées par Google et il ne les indexera pas.
Faut-il les traiter ? Cela dépend
- Si on a affaire à une syntaxe d’url qui est tantôt active, tantôt inactive : cela vaut le coup de les traiter toutes de la même façon. Il y’a des chances que la proportion de ces pages qui sera active augmentera une fois qu’elles seront intégrées dans l’arborescence
- Si vous avez affaire à une syntaxe d’urls qui n’est jamais active : en général on les traitera comme des pages orphelines parasites (voir plus haut).
- on peut faire une exception si vous pensez que ces pages devraient faire partie de l’arborescence, et si elles ne présentent pas de problèmes de qualité. Dans ce cas on peut essayer de voir si elles ont de meilleurs résultats une fois dans l’arborescence
Pourquoi traiter les pages orphelines est un chantier intéressant ?
Notons pour commencer que traiter les pages orphelines n’a d’intérêt que si le site a déjà quelques milliers de pages, et/ou comporte des milliers de pages identifiées comme orpheline.
En dessous de ce seuil, traiter tous les cas peut représenter autant de travail que pour un plus gros site, mais avec moins de gains de trafic au bout : le ROI du chantier risque de ne pas être suffisant.
Mais au delà de cette limite, ce chantier peut avoir deux types d’impacts bénéfiques :
- récupérer les « vraies » pages orphelines dans l’arborescence permet de capter plus de trafic : une fois dans l’arborescence, on peut espérer des gains de positions, ou les pages vraies pages orphelines inactives, plus de pages de ce type qui deviennent actives.
- éviter que Google ait une vision erronée de la qualité de vos pages : s’il ne voit plus que les urls de l’arborescence, la proportion de pages doublons, ou de faible qualité qu’il pourra crawler, parser et indexer sera beaucoup plus faible. Ce nettoyage des urls crawlées produit parfois des bénéfices spectaculaires.
Dans un prochain article, nous verrons comment gérer le cas de pages que Google ne crawle pas ou n’indexe pas…
Ce contenu vous a plu ?
Inscrivez-vous gratuitement à notre newsletter et recevez chaque semaine l’actualité du SEO directement dans votre boîte email. Vous pouvez vous désabonner à tout moment !