

Ce tutoriel reprend la méthodologie développée dans cet article https://www.screamingfrog.co.uk/how-to-compare-crawls/.
On vous explique comment comparer les crawls à l’aide de Screaming Frog SEO Spider en français et comment analyser les différences entre les deux crawls quand on choisit ou non le mode de crawl JavaScript.
La comparaison de crawl permet de monitorer la progression des problèmes et de détecter des opportunités de référencement.
La fonction de comparaison de crawl vous permet de :
- Comparez les données qui ont changé dans tous les onglets et filtres de l’outil.
- Comparez la structure du site et les changements dans les répertoires, les pages et la profondeur de crawl entre les crawls.
- Détectez des changements tels que les titres de page, la profondeur d’exploration, le nombre de mots, les liens internes, le contenu…
Nous allons vous présenter deux méthodes pour lancer une comparaison de crawl.
Réaliser les deux crawls : en mode « texte » (SSR) et en mode « Javascript » (CSR)
Le choix entre les deux modes s’effectue à l’aide du menu Configuration>SEO Spider, en cliquant sur l’onglet rendu
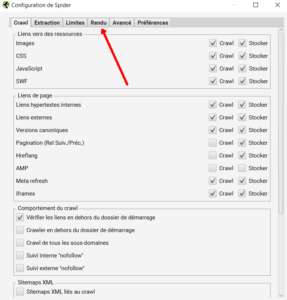
Ensuite : vous pouvez choisir entre crawler le site en mode texte (version SSR, Server Side Rendering) ou en mode JavaScript (version JS, avec rendition JavaScript).
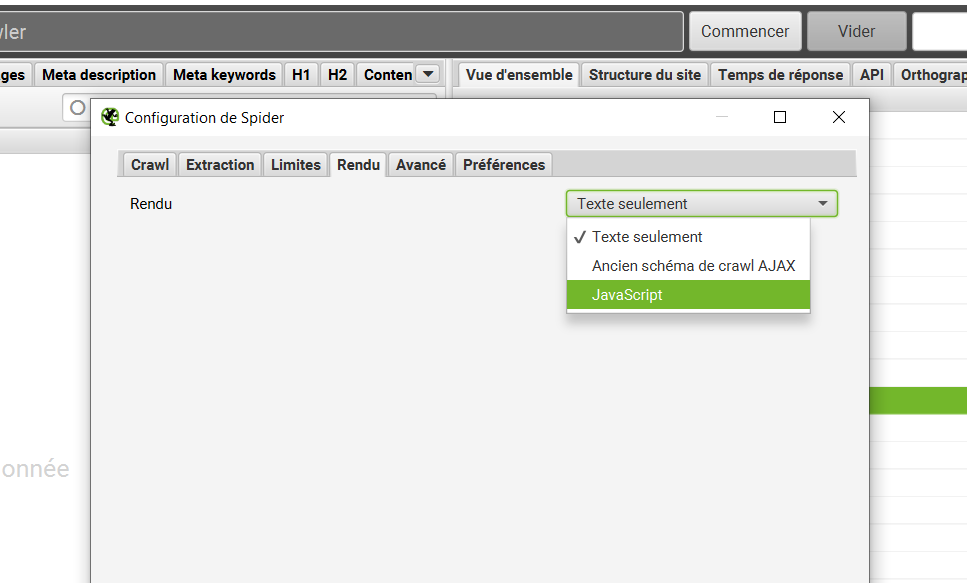
Le mode Javascript comporte un certain nombre de réglages, nous vous recommandons de laisser les paramétrages par défaut, sauf si vous avez un gros site et qu’il faut diminuer la place prise par le crawl dans la base de données.
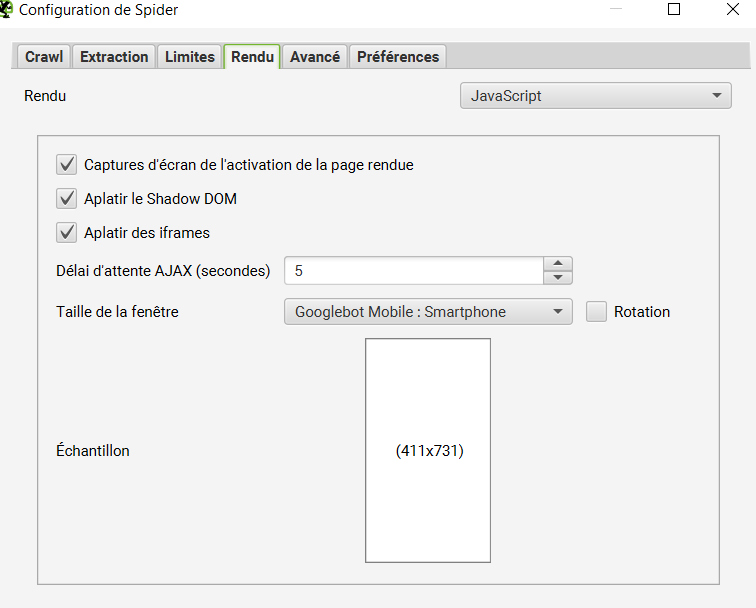
Pour pouvoir comparer le HTML rendu en Javascript et le HTML généré côté Serveur, il faut cocher les cases situées tout en bas de l’onglet extraction :
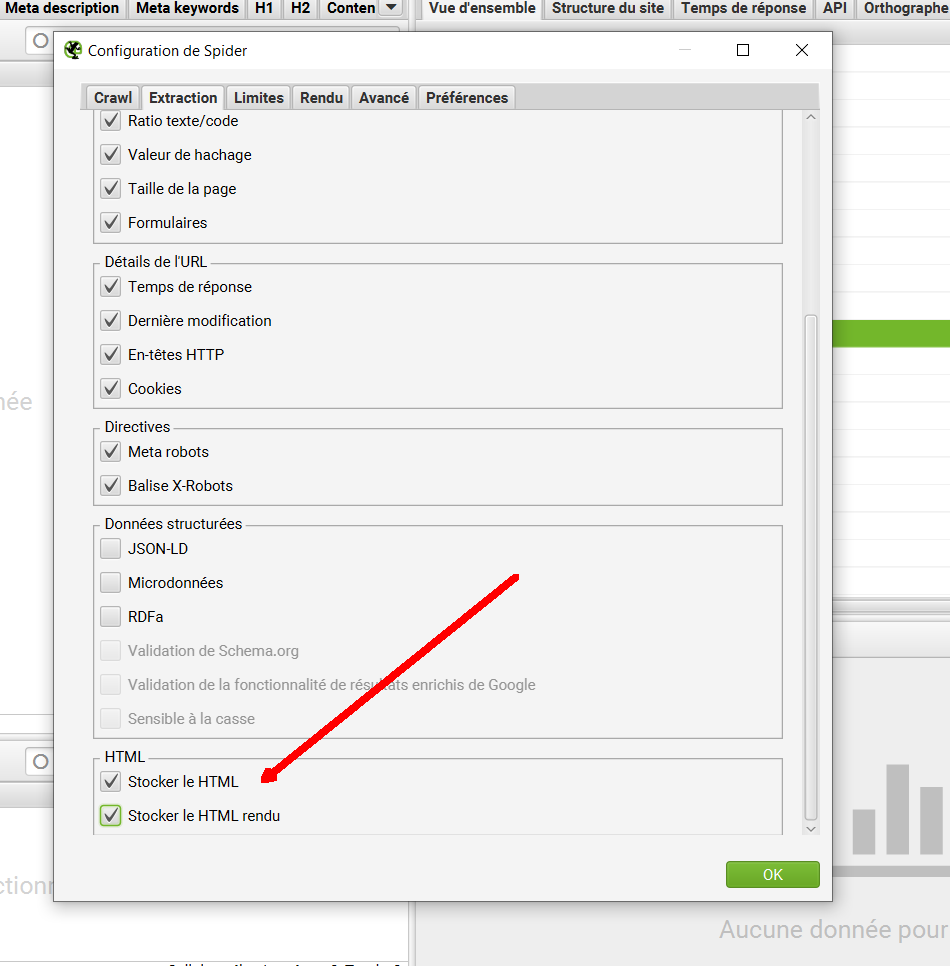
N’oubliez pas cette étape : elle est indispensable pour pouvoir déboguer facilement la rendition en Javascript de votre site. Notez qu’elle n’est utile que si vous crawlez le site en mode Javascript.
Sélectionnez le mode de stockage en base de données
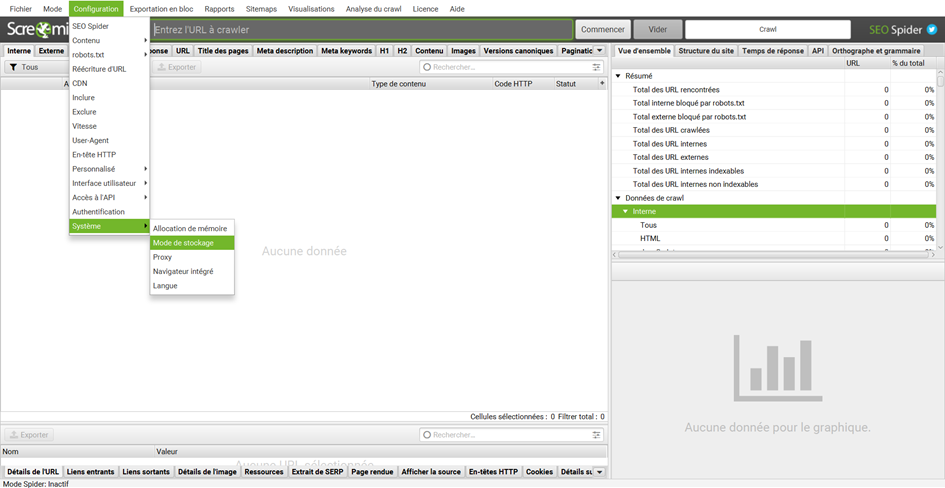
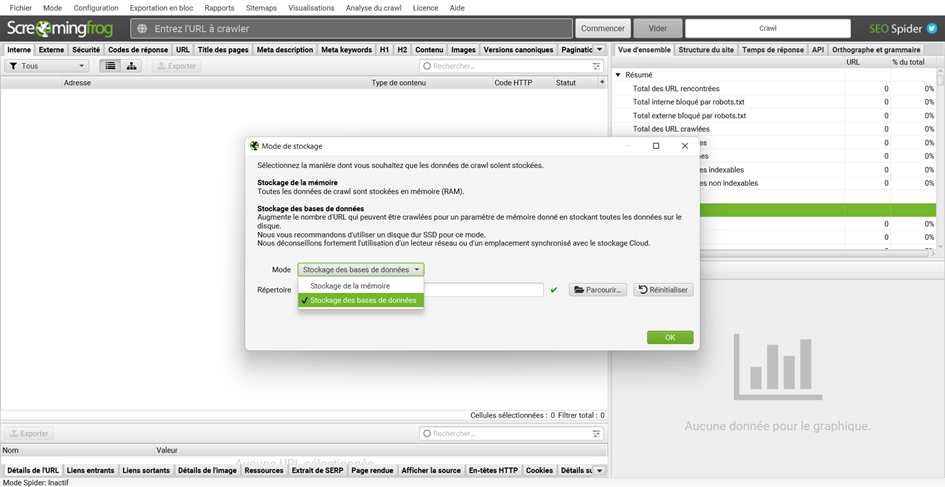
Pour basculer vers le stockage en bases de données, il faut aller dans Configuration > Système > Mode de stockage puis changer le Mode en Stockage des bases de données.
Réalisez les deux crawls, et comparez les
Tous les crawls dans ‘Fichier > Crawls’ peuvent être comparés. Les crawls plus anciens qui sont enregistrés en tant que fichiers .seospider n’apparaîtront pas dans le menu ‘Fichier > Crawls’ car ce ne sont pas des fichiers de base de données.
Cependant, ils peuvent être importés en ouvrant l’ancien crawl soit en cliquant sur le fichier, soit en utilisant ‘Fichier > Importer’ dans l’application. Ils seront convertis au format de base de données, stockés et disponibles pour la comparaison de crawl.
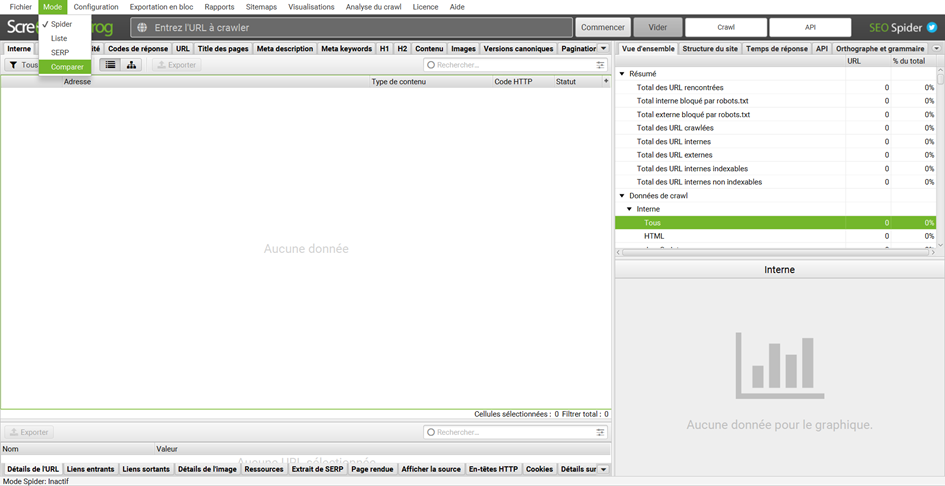
Pour comparer deux crawls vous devez aller dans Mode > Comparer.
Si vous avez un crawl d’ouvert le message suivant peut s’afficher « Le changement de mode va effacer vos résultats, voulez-vous vraiment continuer ? ». Vous pouvez répondre oui sereinement, le crawl sera sauvegardé dans votre base de données.
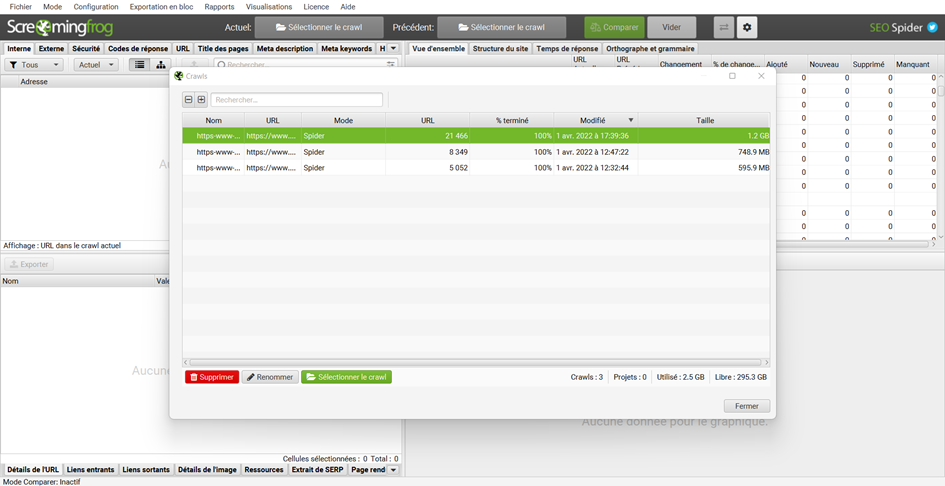
Vous pouvez ensuite cliquer sur Actuel : Sélectionner le crawl et bien choisir le crawl le plus récent puis cliquer sur Précédent : Sélectionner le crawl et choisir le plus ancien.
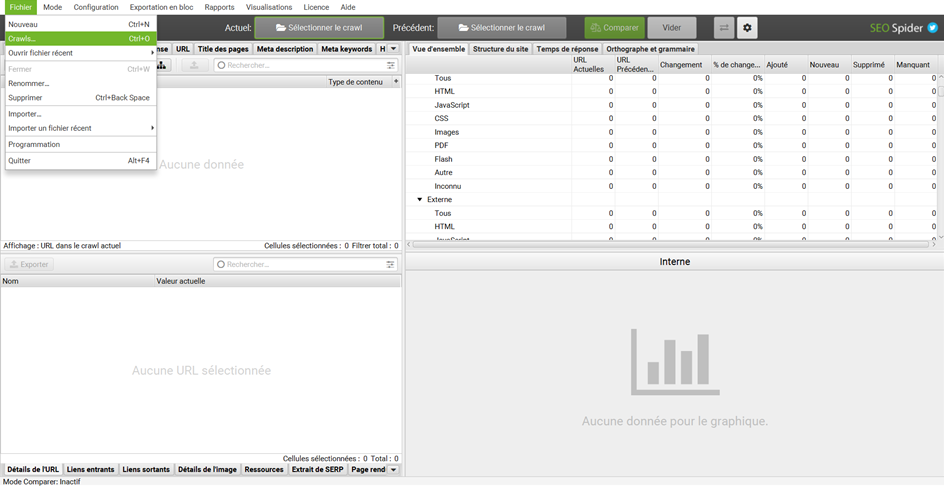
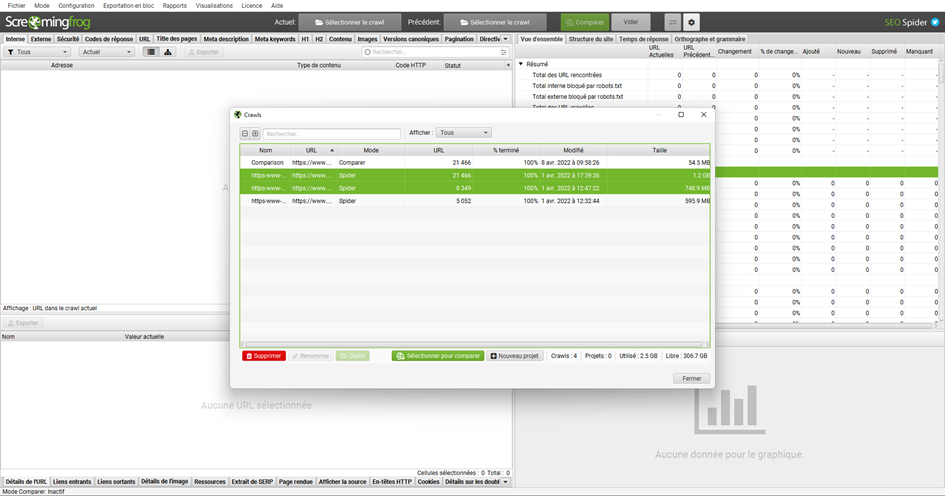
Vous pouvez aussi aller dans Fichier > Crawls… et sélectionner les deux crawls que vous souhaitez comparer, grâce à la touche Ctrl (ou la touche ‘command’ sous macOS), avant de cliquer sur Sélectionner pour comparer.
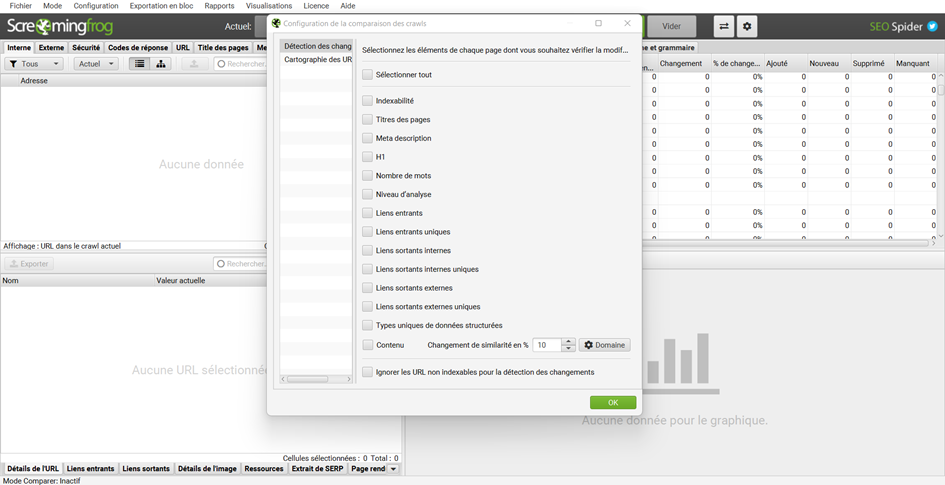
La configuration de la comparaison de crawls est accessible via la roue dentée sur le côté. Vous pouvez sélectionner les points qui vous intéressent, nous vous conseillons de cliquer sur sélectionner tout.
Les points à regarder en priorité :
- Y’a-t’il des changements dans les statuts d’indexabilité ? Le scénario castastrophe, ce sont les urls comportant des meta robots avec la valeur d’attribut noindex en SSR (sans javascript) et « index » ou rien en CSR (avec JavaScript). D’une manière générale, toutes les incohérences entre les balises SEO en SSR et en CSR peuvent générer des effets de bord plus ou moins sérieux. La bonne implémentation, c’est d’ajouter les balises SEO dans le head en SSR (sans JS) et de ne pas les modifier (y compris leur contenu) en CSR (avec JS). Si vous ne générez pas les balises SEO côté serveur, alors vous pouvez les créer en CSR (avec JS) à condition que la génération soit ultra rapide et ne consomme pas trop de ressources côté Googlebot !
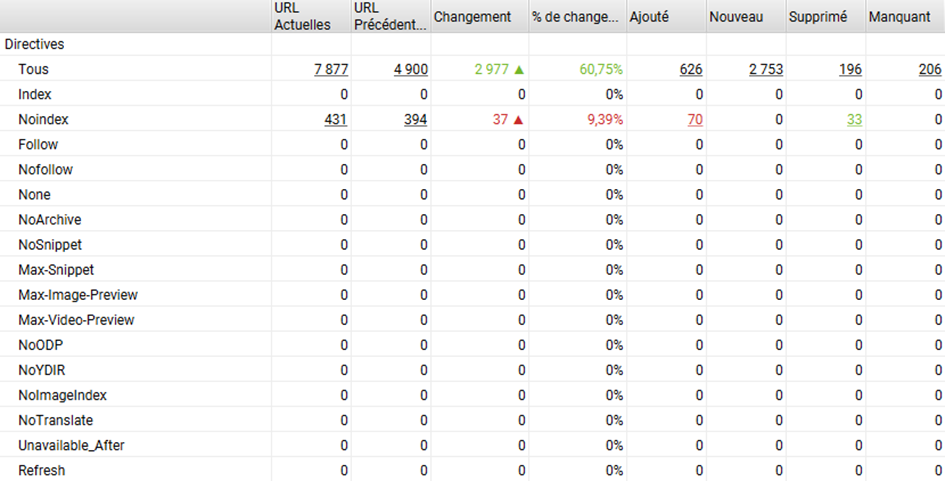
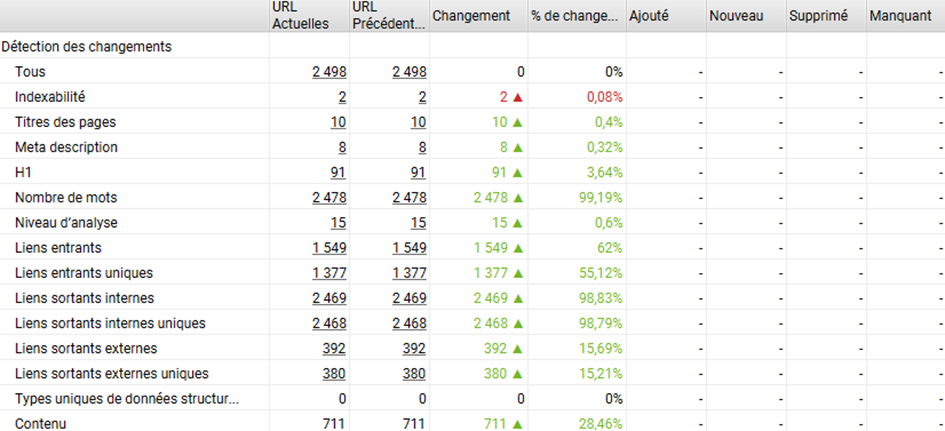
Dans le rapport de comparaison, on peut voir que les balises SEO montrent des différences entre version SSR et CSR => cela mérite une analyse plus détaillée pour identifier ces différences.
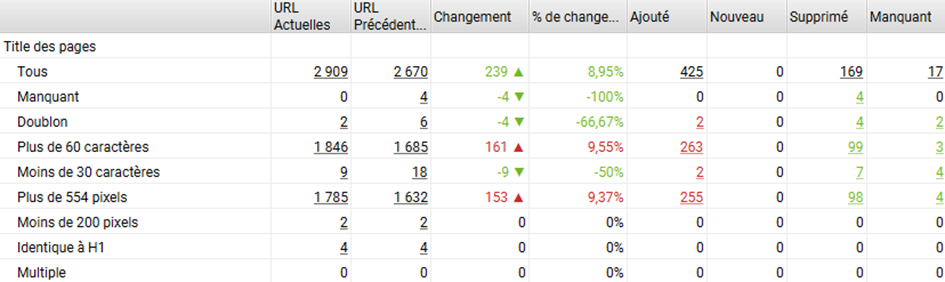
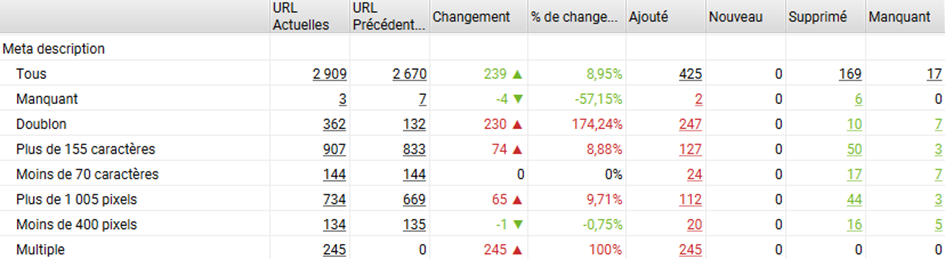
- Y’a-t’il des changements dans le maillage interne ? Il est possible que le code généré en javascript montre une liste de liens différente entre la version SSR et CSR. Et cela peut se traduire par des changements sur la profondeur des urls (négatif ou positif) ou sur le pagerank interne. C’est ce que l’on voit dans l’exemple ci-dessous : le maillage en version JS est très différent (même si la profondeur reste grosso modo la même en moyenne).
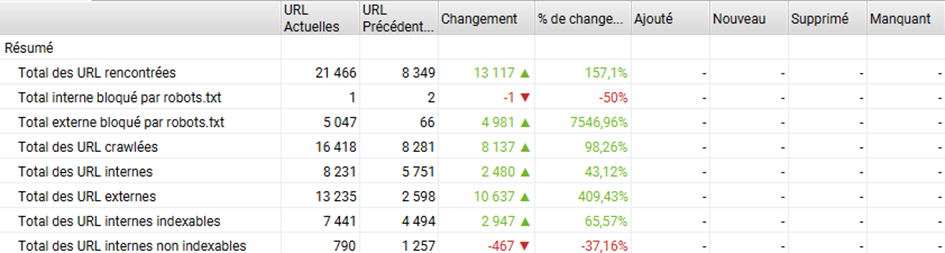

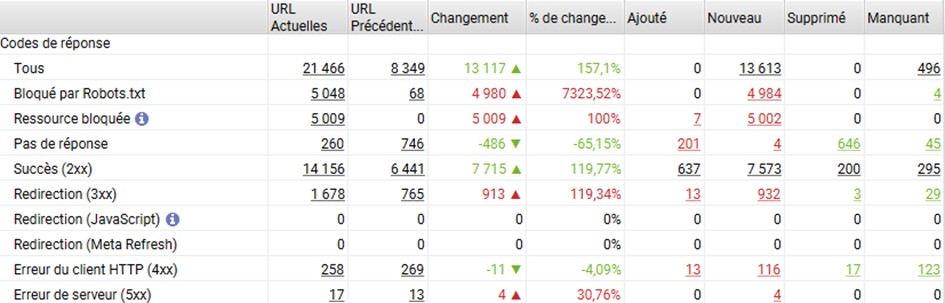
- Autre point : quelles différences entre la version CSR et SSR du point de vue de l’explorabilité ? Quels codes d’erreur sont renvoyés, quelles pages sont bloquées par le robots.txt, et quelles sont les différences ?
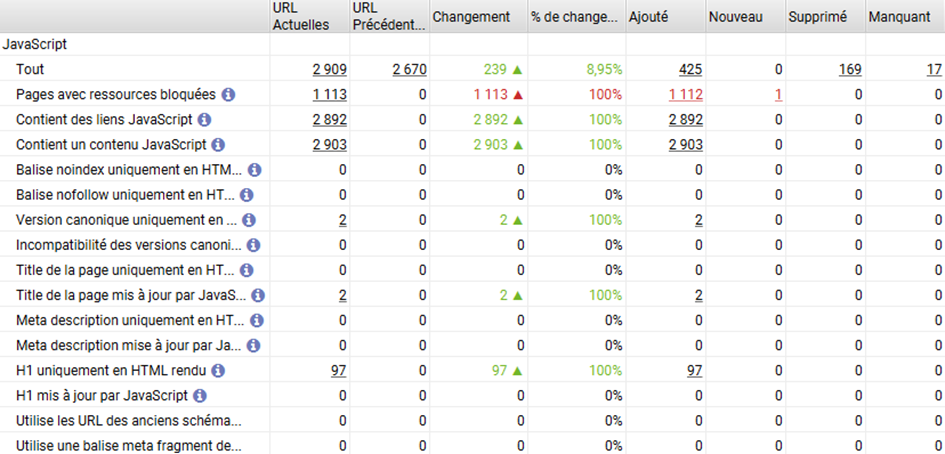
- C’est intéressant également de voir dans les rapports si des ressources utiles à la rendition Javascript sont bloquées.
Pour approfondir : quelles différences de HTML entre la version JS et la version SSR (texte)
Enfin, il est possible de regarder de près les différences entre vos versions CSR et SSR dans Screaming Frog.
Si vous soupçonnez des incohérences entre la version SSR et CSR, ou si votre version rendue avec un framework JS semble ne pas fonctionner comme prévu, vous pouvez vérifier les deux versions du HTML facilement avec Screaming Frog.
Pour cela, pas besoin de deux crawls, juste du crawl en mode JS avec les deux cases cochées : stocker le HTML, et stocker le HTML rendu.
Vous pouvez commencer l’analyse en regardant ce que donne la capture d’écran sur l’onglet « page rendue ».
Elle permet de voir si l’apparence de la page vue par un Google Chromium comme Googlebot est différente de la page que vous voyez en tant qu’utilisateur normal. Si tel est le cas, c’est que vous avez un peut être un souci.
Ensuite, en cliquant sur l’onglet « afficher la source » et en cochant la case « Montrer les différences », vous détecterez immédiatement les changements entre la version SSR et CSR. Certains seront attendus, d’autres non.
Dans l’exemple ci-dessous, on change de version du HTML entre la version SSR et CSR, sans véritable raison. Ce changement de code rend une partie du code non valide.
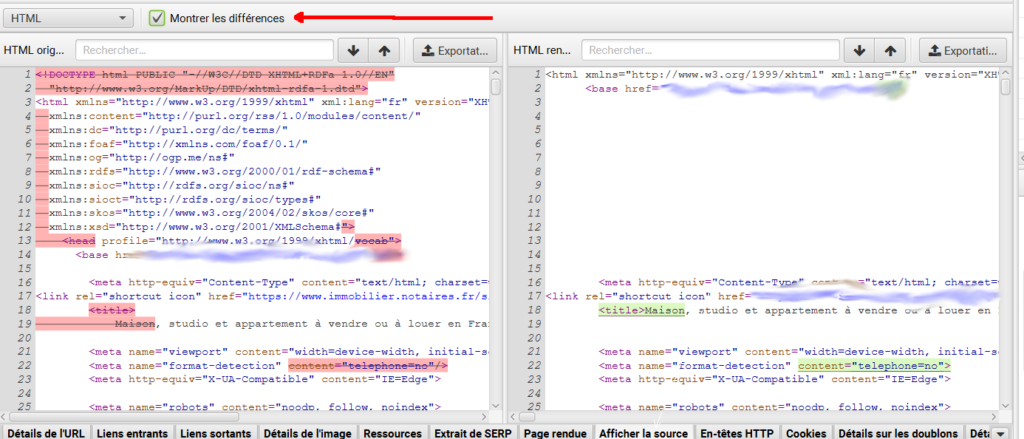
Screaming Frog : un formidable outil pour recetter et déboguer vos sites faits avec des frameworks Javascript.
Les versions récentes de Screaming Frog comportent donc toute une série de fonctionnalités très utiles pour détecter les anomalies que comportent le HTML rendu par du code Javascript. Si vous n’utilisez pas de frameworks JS, c’est déjà intéressant de vérifier que votre contenu et votre arborescence peuvent être crawlées et indexées de la façon attendue.
Si vous utilisez des frameworks comme AngularJS, VueJS, ReactJS ou d’autres, Screaming Frog est un outil très pratique pour déboguer ce type de site.
A utiliser sans modération.
Si vous avez des questions, n’hésitez pas à les poser en commentaire.
Ce contenu vous a plu ?
Inscrivez-vous gratuitement à notre newsletter et recevez chaque semaine l’actualité du SEO directement dans votre boîte email. Vous pouvez vous désabonner à tout moment !