
Google se présente comme une entreprise « AI First », qui est censée mettre l’intelligence artificielle au coeur de tous ses produits. Et c’est vrai que les équipes de chercheurs de Google sont en pointe sur ces sujets, et que nombre de leurs services démontrent la maîtrise de la firme de Mountain Vieux dans ce domaine.
Mais un produit, et ce n’est pas le moindre, n’est toujours pas vraiment AI First : son moteur de recherche… Mais cela ne veut pas dire qu’il n’y a pas d’IA dans l’algorithme, et surtout pas que cela restera comme cela dans les prochaines années.
Google vient de communiquer sur son blog The Keyword sur les fonctionnalités à base d’Intelligence Artificielle qui sont réellement embarquées dans le moteur. Et même si cela signifie que l’algorithme ne repose pas du tout à 100% sur l’IA, on voit quand même le deep learning et les modèles de langage préentrainés joue un rôle de plus en plus important.
Décodons ensemble ce que nous dit Google.
Première fonctionnalité : Rankbrain
Lancé en 2015 par Greg Cerrado, Rankbrain est la première fonctionnalité à base d’IA que Google a utilisé pour son algorithme de classement.
RankBrain nous aide à trouver des informations que nous ne pouvions pas trouver auparavant en comprenant plus largement comment les mots d’une recherche sont liés à des concepts du monde réel. […]
Grâce à ce type de compréhension, RankBrain (comme son nom l’indique) est utilisé pour aider à classer – ou décider du meilleur ordre pour – les principaux résultats de recherche. Bien qu’il s’agisse de notre tout premier modèle d’apprentissage profond, RankBrain reste l’un des principaux systèmes d’IA qui alimentent la recherche aujourd’hui.
Pandu Nayak
Rankbrain est donc utilisé pour identifier les documents qui sont des bonnes réponses à des questions des internautes. Mais il y’a plusieurs choses que Google ne dit pas :
- Rankbrain n’a de valeur ajoutée que sur des requêtes en langage naturel. Pas lorsqu’elles sont formulées sous forme de quelques mots clés
- Rankbrain s’appuie sur un type de modèle de langage dont les possibilités sont limitées par rapport aux modèles de 2022 : il s’agit des word embeddings.
- Rankbrain sert surtout à convertir des requêtes sous formes de questions en « concepts ». Par exemple la question « quelle est la meilleure pizza à Levallois » appelle le concept de pizzeria. Ce qui permet de faire remonter les pages étiquetées comme appartenant à des sites de pizzeria. Ce que Google sait faire, de manière moins fine, depuis 2013. Rankbrain est donc une simple amélioration d’Hummingbird.
- Rankbrain sert surtout à faire remonter de temps en temps des pages que les scores classiques de similarité textuelle entre requête et document n’auraient pas placé en tête des résultats. Son impact n’est pas majeur.
Par contre Rankbrain donne sa chance à des pages qui ne sont pas « conçues » pour se positionner dans Google, ce qui change un peu la donne pour le SEO
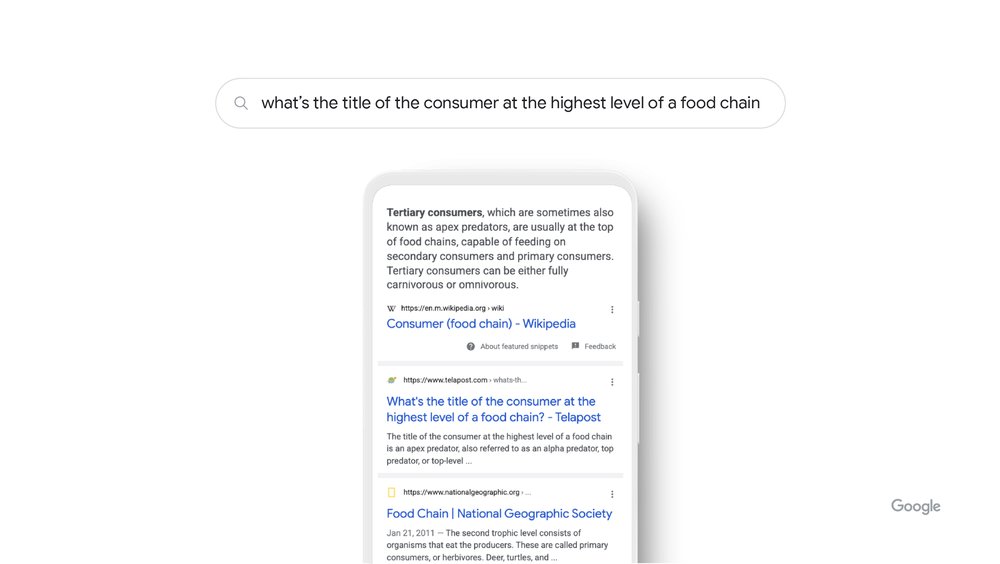
Deuxième fonctionnalité : le Neural Matching
Le Neural Matching consiste utiliser un réseau de neurones pour identifier les relations entre les concepts et les termes contenus dans une page web. Il est utilisé dans le moteur depuis 2018, et a été étendu à la recherche locale en 2019.
Si Rankbrain sert à mieux comprendre les concepts appelés par les questions (donc à mieux comprendre les requêtes), le Neural Matching permet à Google de mieux comprendre les concepts contenus dans les pages webs (donc dans les réponses). Si Rankbrain donne des concepts précis, le Neural Matching va chercher des notions plutôt larges, identifiées par plusieurs mots, pour identifier des pages pertinentes sur une requête.
Il semble que cela soit aussi un outil de « semantic matching » similaire à une fonctionnalité implémentée chez Bing :
Troisième fonctionnalité : BERT
BERT est un nouveau modèle de langage à base de Transformers, déployé fin 2019 au sein de l’algorithme de Google. Par rapport aux word embeddings embarqué dans Rankbrain, BERT représente un véritable saut quantique aussi bien dans la complexité du modèle, les informations embarquées dans le modèle et ses capacités.
Ce modèle est beaucoup plus doué que les précédents pour différentes tâches. Il permet d’identifier assez finement, si vous enlevez un mot au milieu d’une phrase, quel est le mot manquant.
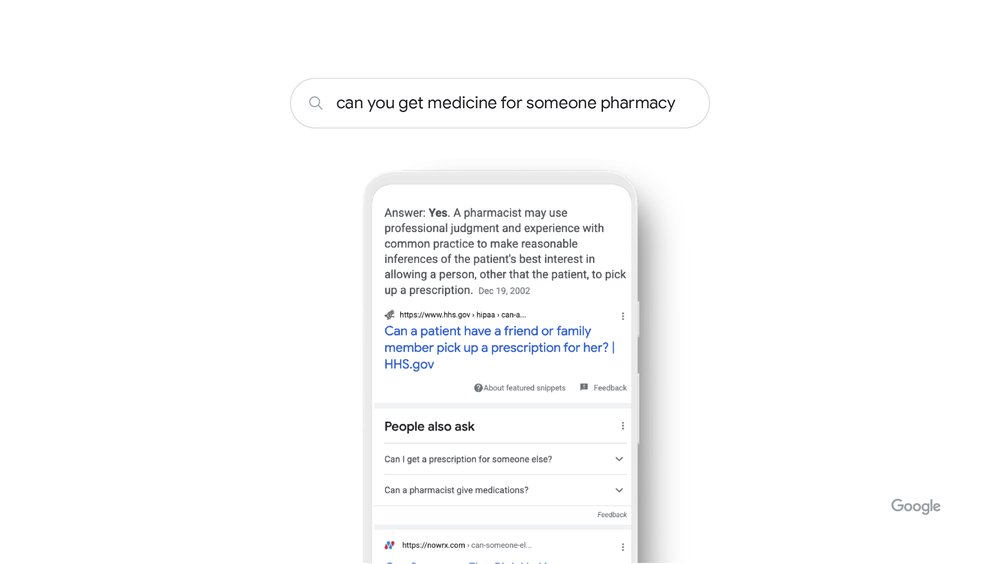
BERT permet de prédire aussi si un texte est une bonne réponse à une question, ce qui explique pourquoi Google l’a utilisé pour améliorer ses « featured snippets ». D’une manière générale, BERT est un bon outil pour prédire quelle séquence de termes suivra un texte de départ. Et permet une représentation vectorielle d’ensembles de mots plus longs que les modèles précédents.
Il semble que Google, d’après les explications de Panda Nayak, embarque les coordonnées sémantiques produites par le modèle BERT dans des vecteurs stockés dans son index, ainsi que dans le processeur de requêtes. Ce qui permet de produire des pages de résultats plus pertinentes. Le modèle n’est toutefois pas totalement conçu pour cet usage, ce qui explique pourquoi l’impact de BERT sur les SERPs est assez limité malgré tout.
De plus le modèle BERT a été entrainé surtout sur des textes en anglais, et est plus employé sur les versions anglophones de Google que sur les autres. Mais sur la version anglaise, il joue un rôle dans le classement produit sur la page de résultats sur une proportion importante des requêtes.
Et MUM ?
MUM, le tout nouveau modèle de langage préentrainé de Google, est encore expérimental. Comme nous l’avions écrit dans cet article :
Google a indiqué à Barry Schwartz de Seroundtable.com qu’ils communiqueraient lorsque le modèle MUM commencera à être embarqué dans l’algorithme de classement générique.
Conclusion : attention à ce qui va se passer d’ici deux ou trois ans
Pour le moment, l’IA a surtout permis d’améliorer certains aspects du fonctionnement du moteur de recherche Google, sans forcément que les utilisateurs voient de grands bouleversements ou un saut quantique dans la qualité des résultats.
Mais les nouveaux modèles de langage préentrainés comme GPT-3, Turing NLP, MT-NLG, Wu Dao etc. ont moins de deux ans ! La recherche sur les applications de ces modèles ne fait que commencer. Et les modèles spécialisés dans les tâches d' »ad hoc retrieval » (un terme de jargon scientifique pour indiquer une recherche dans un moteur comme Google et Bing) sont encore dans les labos.
A la vitesse où vont les choses, il est possible que l’on voit apparaître un algo beaucoup, beaucoup plus doué dans la découverte des pages pertinentes en quelques années seulement.
Pas sûr que toutes les recettes de cuisine pour optimiser les sites pour le SEO marchent encore avec ce type d’algos… Déjà, elles ont pris du plomb dans l’aile ces dernières années.
Pour cette raison, chez Neper, nous étudions déjà dans les Neperian Labs les modèles de langage préentrainés. Cela nous permettra d’adapter en temps utile nos méthodologies, mais aussi de proposer de nouveaux outils embarquant ces nouvelles technologies pour différents usages sur le web.
L’évolution de l’algorithme dans les années à venir risque bien de se révéler passionnante.
Le billet de blog de Pandu Nayak sur The Keyword
https://blog.google/products/search/how-ai-powers-great-search-results/
Ce contenu vous a plu ?
Inscrivez-vous gratuitement à notre newsletter et recevez chaque semaine l’actualité du SEO directement dans votre boîte email. Vous pouvez vous désabonner à tout moment !