

Il y’a quelques semaines, Google annonçait lors de l’événement Google I/O un nouveau modèle de langue beaucoup plus puissant que BERT : MUM.
Nous avons eu l’occasion lors de cet article de signaler qu’il s’agissait plus d’un coup de comm’ de Google que d’une véritable annonce. MUM est encore dans une phase de tests et de mise au point, et nous n’en sommes pas encore à voir des applications sérieuses dans l’algorithme de classement.
Il semble néanmoins que Google ait décidé d’exploiter à fond les avancées liées au modèle dans sa communication. Pandu Nayak, le patron du département Search vient de publier le 29 juin dernier un billet sur le Blog the Keyword décrivant une première utilisation de MUM.
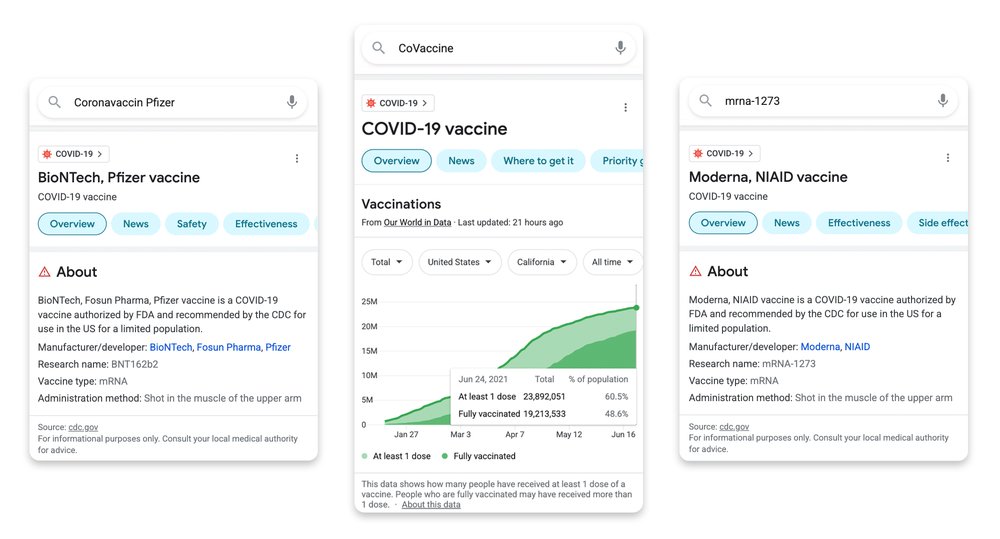
MUM utilisé par Google pour découvrir toutes les variantes de dénomination liées aux vaccins contre la Covid 19
Dans son billet, Pandu Nayak nous apprend que son équipe a été confronté à un problème : comment reconnaître toutes les variantes de graphie et de dénomination pour les vaccins contre la Covid 19 ? Le vaccin Astra Zeneca a changé de nom. Celui de Johnson et Johnson est parfois appelé Janssen. Les dénominations changent en plus selon les pays et les langues.
Ils ont alors eu l’idée de demander aux chercheurs de Google de tester si le modèle de langue MUM était en mesure de les aider à découvrir toutes ces variantes, et dans les différentes langues sur lesquels MUM est entrainé (soit plus de 70 langues différentes).
Et selon eux, l’exploitation des données du modèle a permis de découvrir facilement près de 800 variantes.
Ces résultats ont d’abord été vérifiés à la main, puis ils ont intégrés ces variantes dans le requêteur. On peut deviner, sans trop de risques d’erreur, que l’intégration permet de reconnaître que la requête porte sur la vaccination contre le Covid, ce qui déclenche l’affichage d’une page de résultats spéciale comportant beaucoup de données et d’informations filtrées par Google sur le sujet.
Comment décoder la communication de Google sur ce sujet ?
Si on veut aller plus loin, on s’aperçoit qu’une fois de plus on est dans de la communication pure.
Qu’un modèle de langue comme BERT, MUM, GPT-3 ou Switch-C soit capable de ce genre de prouesses n’a rien de surprenant. Ils sont conçus pour permettre cela.
Mais une fois de plus, on doit noter qu’il est clair qu’il n’y a aucune intégration sérieuse de MUM dans l’algorithme : des données ont été extraites, sur une famille de requêtes très limitée en taille et en diversité. Elles ont été revues à la main pour être ensuite ajoutées manuellement dans le système… On est loin encore des fonctionnalités révolutionnant l’algorithme de recherche que Pandu Nayak laissait entrevoir lors du Google I/O pour le futur de l’algorithme de classement.
Mais une constante se révèle : Google mise sur MUM pour sa communication, un peu comme ils ont longtemps misé sur le Pagerank. Cela suppose un minimum de confiance sur le fait que ce nouveau modèle va leur permettre de multiplier les résultats (et les annonces) de ce genre dans les prochains mois. Il y’a donc aussi de fortes chances que MUM finisse par propulser de plus en plus de fonctionnalités dans le moteur de recherche et l’algorithme de classement.
Chez Neper, on se félicite de plus en plus d’avoir fait de ces sujets le domaine de recherche de notre équipe de R&D : les Neperian Labs.
Le lien vers le billet de Pandu Nayak
https://blog.google/products/search/how-mum-improved-google-searches-vaccine-information/
Ce contenu vous a plu ?
Inscrivez-vous gratuitement à notre newsletter et recevez chaque semaine l’actualité du SEO directement dans votre boîte email. Vous pouvez vous désabonner à tout moment !