

John Mueller avait déjà indiqué en 2020 que les mots clés présents dans les urls avaient un poids très faible dans l’algorithme de classement.
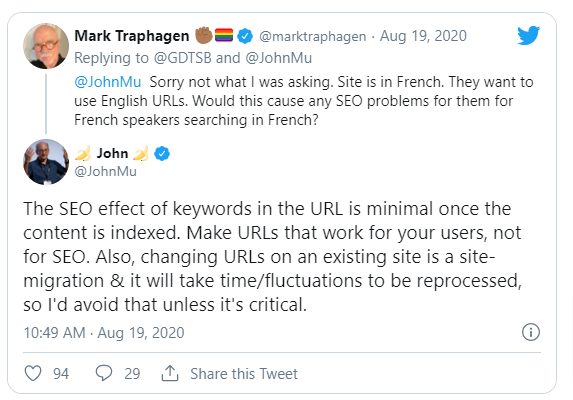
Il vient de rappeler ce point dans un Hangout récent :
Donc une fois le contenu indexé, les mots clés dans l’url finissent par compter très peu dans l’algorithme de classement.
Conclusion : lorsque les outils de type CMS mettent en avant leur capacité à fabriquer des « pretty urls » comme l’alpha et l’omega de leur compatibilité SEO, il y’a clairement tromperie sur la marchandise ! La vérité est ailleurs…
Google utilise les mots clés dans l’url comme signal lors de la phase d’exploration
Depuis très longtemps (et au moins depuis 2009), Google utilise une approche « prédictive » lors de son exploration. L’objectif est de deviner si une url va être intéressante à indexer avant même de l’avoir téléchargée. Et pour faire cela, Google exploite les informations incluses dans l’url, à savoir le « path » (les répertoires virtuels symbolisés par les / : domaine.com/rep1/rep2) et les mots clés inclus dans l’url. Mais aussi la « query string » (les paramètres), et les indicateurs des urls qui ressemblent à l’url analysée.
Depuis quelques mois, ces « prédictions » sont faites en introduisant une dose d’apprentissage automatique dans le système.
Faut-il arrêter de placer les mots clés de la requête ciblée dans l’url ?
Ces déclarations ont remis la pratique de l’insertion des mots clés correspondant à la requête que l’on cible dans l’url à sa juste place. Il s’agit d’une simple bonne pratique. C’est tout.
Ne pas le faire n’est pas du tout bloquant pour le référencement. Et c’est même très peu gênant.
Mais d’un point de vue expérience utilisateur cela reste évidemment fortement conseillé de le faire, pour avoir des urls faciles à comprendre, notamment lorsqu’on les manipule avec un copier coller.
Ce contenu vous a plu ?
Inscrivez-vous gratuitement à notre newsletter et recevez chaque semaine l’actualité du SEO directement dans votre boîte email. Vous pouvez vous désabonner à tout moment !