

Le fichier robots.txt fait partie du quotidien du site web depuis 1994. Au départ c’était une initiative de Martijn Koster. Et c’est devenu un standard de fait.
Au fil des ans, les propriétaires de site ont pris de mauvaises habitudes concernant le contenu du fichier robots.txt. Google a longtemps contribué à la confusion en s’éloignant des standards initiaux et en supportant de manière officielle ou non certaines syntaxes qu’ils étaient les seuls à savoir interpréter.
Rappel : les directives noindex ne sont plus supportées dans le fichier robots.txt
Grâce à l’intervention salutaire de Gary Illyes de Google (rendons à César…), Google a lancé en juillet 2019 une initiative pour revenir au standard initial. Ils ont vite été suivis par Bing et aujourd’hui le robots.txt est revenu à sa vocation d’origine et les deux moteurs principaux le supportent de manière standard et prévisible.
La directive noindex n’est plus supportée par Google depuis septembre 2019 ! Donc ne l’utilisez plus pour désindexer vos contenus, il faut utiliser :
- soit la balise meta name=’robots’ dans une page HTML
- soit une directive X-Robots-Tag dans un document non HTML (voir l’article du blog Neper sur ce sujet ici : https://www.neper.fr/2021/01/14/tip-comment-bloquer-lindexation-des-images-ou-des-pdfs-x-robots-tag/
NE BLOQUEZ PAS MASSIVEMENT DES URLS DU FRONT OFFICE
En principe, sur un site techniquement bien fait, bloquer l’exploration des URLs visibles par un utilisateur par les moteurs de recherche n’a pas d’utilité.
Ensuite, et c’est moins connu, les URLs bloquées par le robots.txt ont un pagerank, reçoivent du pagerank, mais ne redonnent jamais le pagerank qu’on leur a transmis. Si vous bloquez massivement des URLs qui sont affichées sur votre site par des directives “disallow”, cela peut faire disparaître une part non négligeable du pagerank interne.
En clair, il est recommandé d’éviter de faire trop de liens dans votre maillage interne vers des pages bloquées par une directive “disallow”. La perte de pagerank interne peut-être très significative.
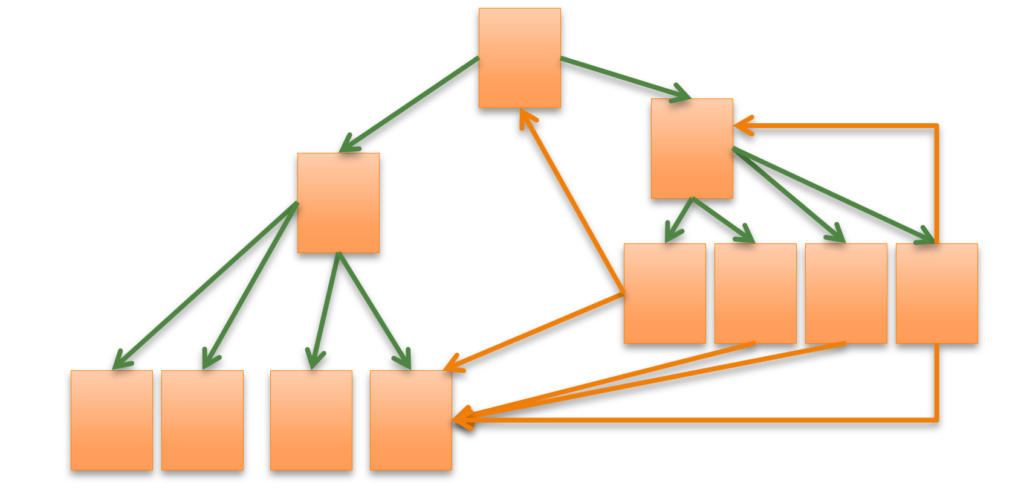
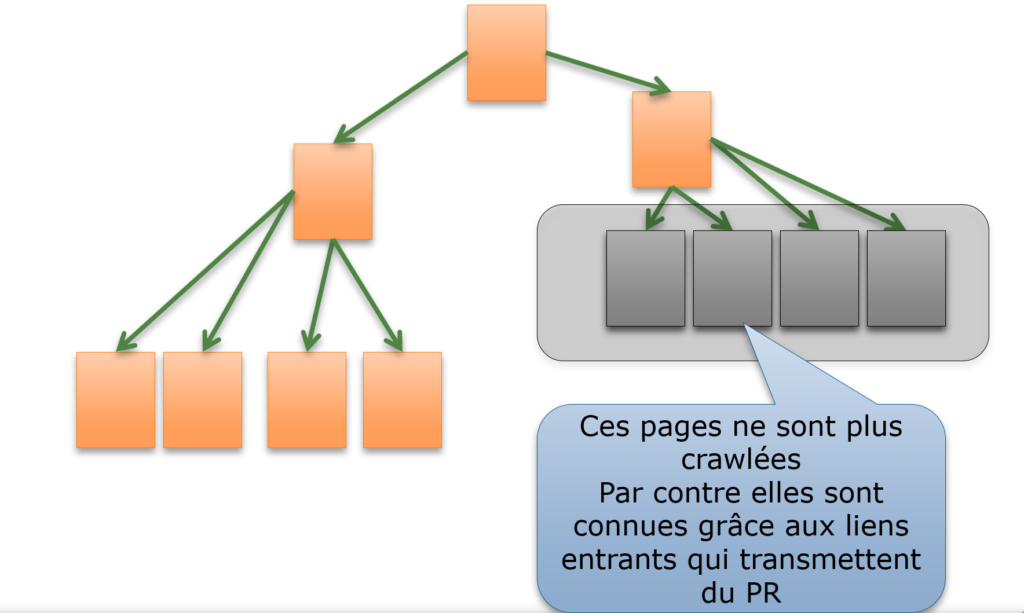
BLOQUEZ BIEN LE CRAWL DES FACETTES ET DES PAGES DU MOTEUR DE RECHERCHE INTERNE
A l’inverse, il est extrêmement utile d’empêcher les moteurs de découvrir les syntaxes des URLs qui correspondent par exemple :
– à des recherches du moteur de recherche interne
– à des filtres créés par une navigation à facettes
Ces URLs ne font pas partie de l’arborescence « normale » du site. Elles ne figurent pas dans les menus (sauf cas exceptionnel). Bloquer ces syntaxes est une bonne idée. Ne pas le faire peut clairement vous empêcher d’avoir un bon référencement, car un grand nombre de pages inutiles seraient crawlées et indexées.
NE BLOQUEZ PAS LES URLS DE FICHIERS CSS, JAVASCRIPT, JSON QUI SONT UTILES POUR UNE RENDITION CORRECTE DE LA PAGE
Sur ce sujet, n’hésitez pas à regarder cette courte video de John Mueller :
Conseil final : relisez la référence sur le contenu du robots.txt et sur son support par Google
Il est fortement conseillé d’utiliser dans le robots.txt des syntaxes standard, parfaitement supportées par TOUS les moteurs de recherche (dont Bing, Yandex, Baïdu, Seznam, Naver…).
Pour prendre connaissance des standards, le mieux est de conseiller le site dédié au protocole robots.txt :
La page de référence de Google :
https://developers.google.com/search/docs/advanced/robots/intro?hl=fr
Et n’hésitez pas à vérifier votre robots.txt à l’aide de l’outil dédié de la Google Search Console.
https://www.google.com/webmasters/tools/robots-testing-tool
(il faut avoir validé la GSC pour ce site pour que ça fonctionne).
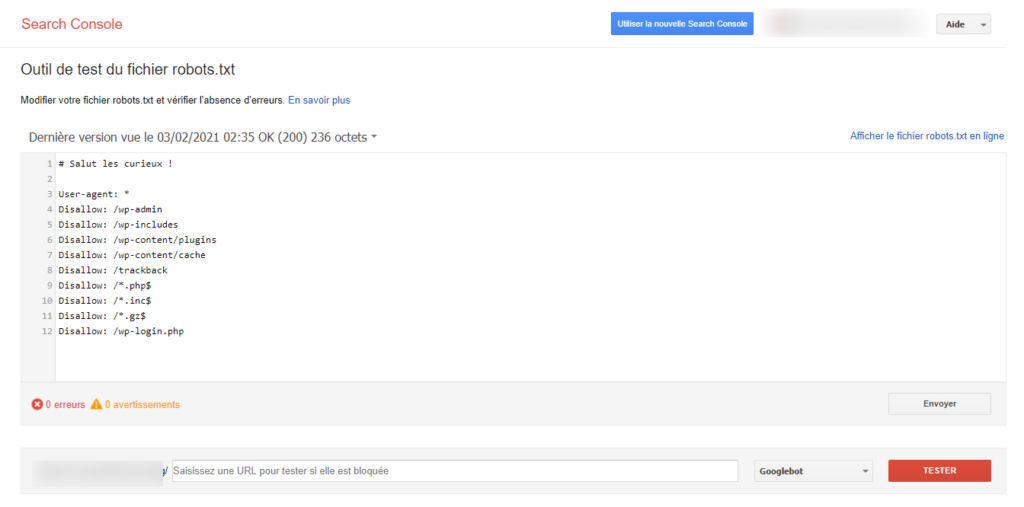
Pour info, l’outil va bientôt être migré dans la nouvelle Search Console, c’est une affaire de jours / semaines.
Ce contenu vous a plu ?
Inscrivez-vous gratuitement à notre newsletter et recevez chaque semaine l’actualité du SEO directement dans votre boîte email. Vous pouvez vous désabonner à tout moment !
Bonjour Philippe et merci pour cet article,
Quid du « nofollow » sur les qui référencent des pages bloquées via un « Disallow » ?
Bonjour Nicolas,
Malheureusement nous n’avons pas compris votre question. Pourriez-vous la reformuler s’il vous plaît ?