

Depuis le lancement de la nouvelle version de la Google Search Console et de son rapport de « Couverture », beaucoup de webmasters s’étaient interrogés sur les nombreuses urls dont le statut était « crawl anomaly ».
Ce type de « statut » est susceptible d’être mentionné lorsque l’on affiche les données sur les urls « exclues »
Le moins que l’on puisse dire c’était que l’origine de ces « anomalies » étaient le plus souvent difficiles à diagnostiquer.
Google vient d’annoncer le 11 janvier dernier qu’ils avaient déployé une nouvelle version du rapport, avec des informations plus détaillées sur les causes de ces anomalies.
Ce qui a changé concrétement :
- le statut « anomalie » lors de l’exploration disparait. Les urls qui étaient comptabilisées sous ce statut doivent désormais être comptabilisées sous des statuts mieux définis.
- Le statut « indexed but blocked » (warning) remplace « submitted but blocked » (error)
- les « soft 404 » sont mieux comptabilisées
- il y’a un nouveau statut « indexed without content » pour les cas où l’url est indexée mais sans que Google ait pu télécharger le contenu (à cause d’un blocage via le robots.txt).
Un diagnostic facilité
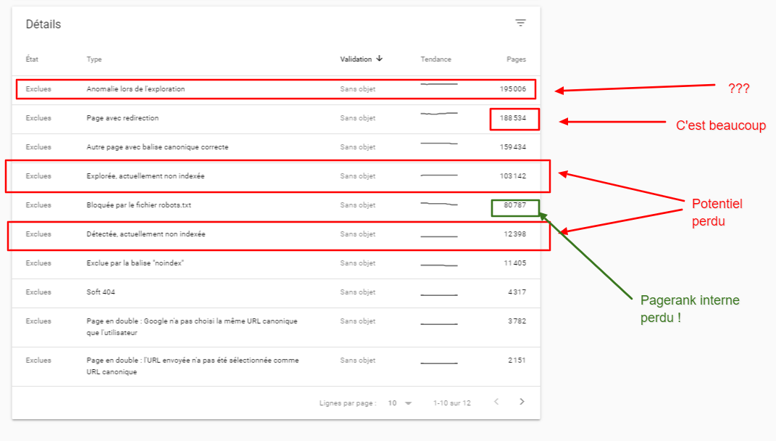
Une meilleure identification des raisons de l’exclusion de l’index permet de faire un meilleur diagnostic. Dans le cas du site dont le rapport figure en exemple ci-dessus, les causes de l’exclusion de plus de 195000 urls faisaient débat en interne. Et bien ces urls sont désormais comptabilisées en … « soft 404 ».
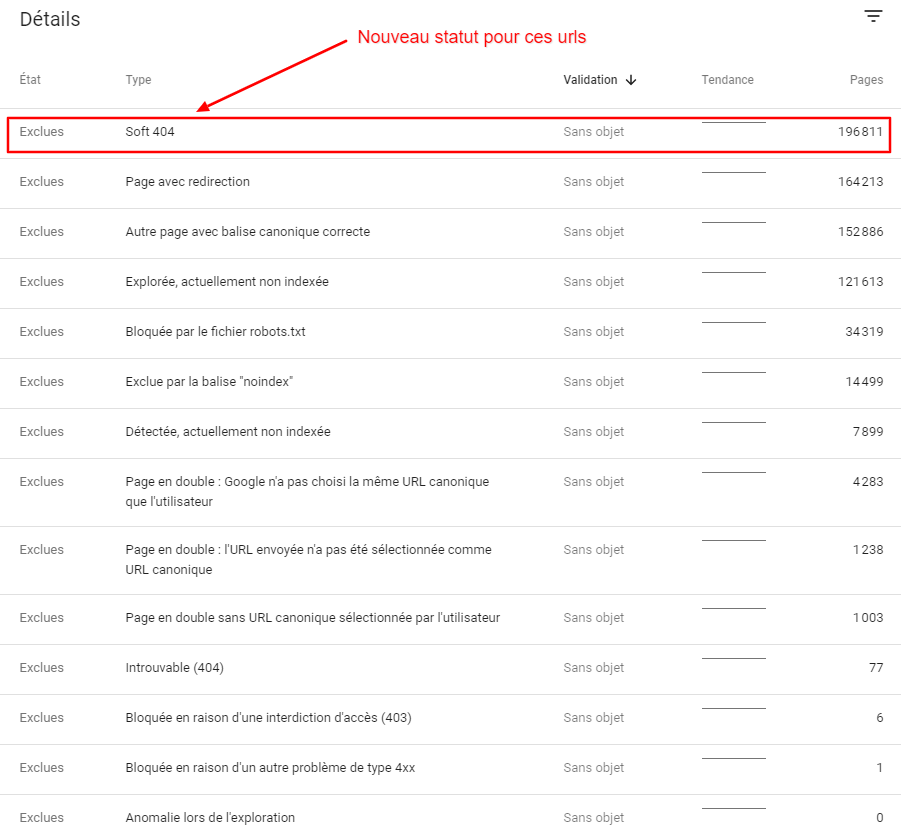
C’est donc la façon de rediriger les pages qui disparaissent sur ce site qui est en cause, car elle amène Google à penser que les urls qu’ils crawlent devraient être des 404 (d’où le statut soft 404). Le débat est clos, et on sait du coup ce qu’il faut faire (changer la règle de redirection pour pointer vers des pages moins génériques, ou faire ce qu’attend Google : renvoyer une 404).
Plus d’informations dans l’article du blog pour les développeurs de Google
https://developers.google.com/search/blog/2021/01/index-coverage-data-improvements